 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSODFormer: Streaming Object Detection with Transformer Using Events and Frames
Paper and Code
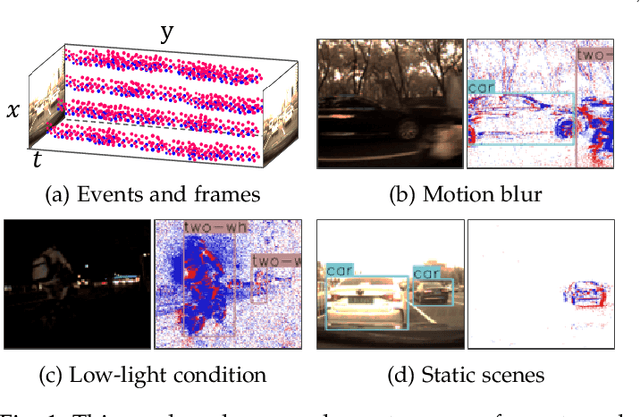
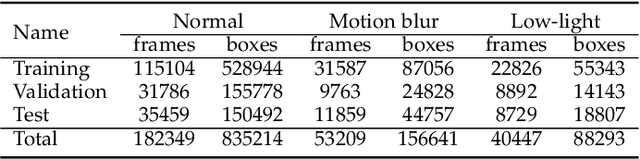

DAVIS camera, streaming two complementary sensing modalities of asynchronous events and frames, has gradually been used to address major object detection challenges (e.g., fast motion blur and low-light). However, how to effectively leverage rich temporal cues and fuse two heterogeneous visual streams remains a challenging endeavor. To address this challenge, we propose a novel streaming object detector with Transformer, namely SODFormer, which first integrates events and frames to continuously detect objects in an asynchronous manner. Technically, we first build a large-scale multimodal neuromorphic object detection dataset (i.e., PKU-DAVIS-SOD) over 1080.1k manual labels. Then, we design a spatiotemporal Transformer architecture to detect objects via an end-to-end sequence prediction problem, where the novel temporal Transformer module leverages rich temporal cues from two visual streams to improve the detection performance. Finally, an asynchronous attention-based fusion module is proposed to integrate two heterogeneous sensing modalities and take complementary advantages from each end, which can be queried at any time to locate objects and break through the limited output frequency from synchronized frame-based fusion strategies. The results show that the proposed SODFormer outperforms four state-of-the-art methods and our eight baselines by a significant margin. We also show that our unifying framework works well even in cases where the conventional frame-based camera fails, e.g., high-speed motion and low-light conditions. Our dataset and code can be available at https://github.com/dianzl/SODFormer.