Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlow-Fast Auditory Streams For Audio Recognition
Paper and Code
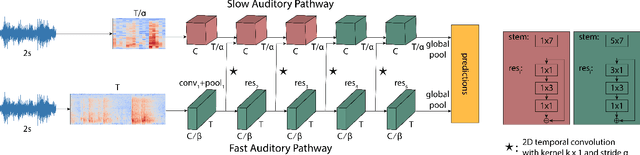
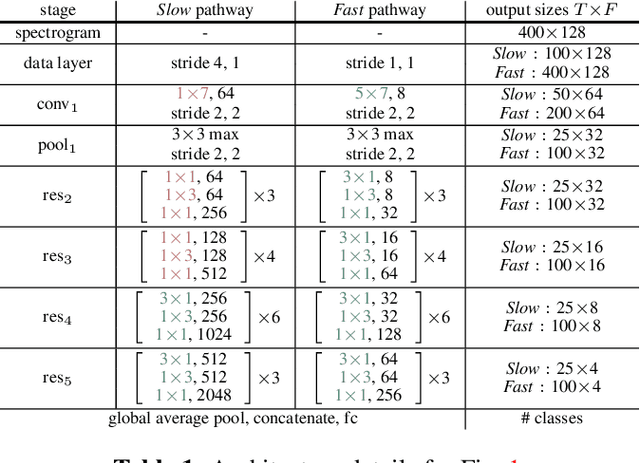
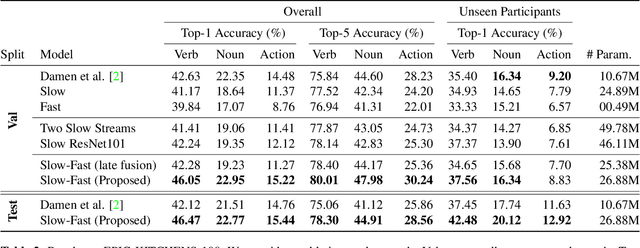

We propose a two-stream convolutional network for audio recognition, that operates on time-frequency spectrogram inputs. Following similar success in visual recognition, we learn Slow-Fast auditory streams with separable convolutions and multi-level lateral connections. The Slow pathway has high channel capacity while the Fast pathway operates at a fine-grained temporal resolution. We showcase the importance of our two-stream proposal on two diverse datasets: VGG-Sound and EPIC-KITCHENS-100, and achieve state-of-the-art results on both.
* Accepted for presentation at ICASSP 2021
View paper on