 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlim-DP: A Light Communication Data Parallelism for DNN
Paper and Code

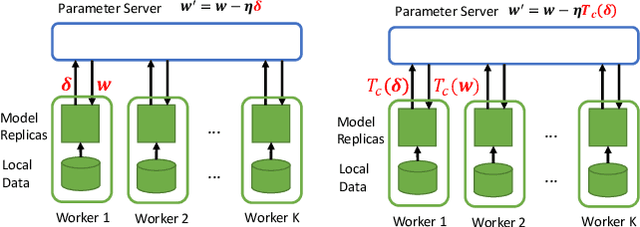

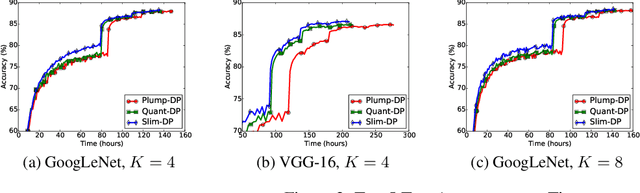
Data parallelism has emerged as a necessary technique to accelerate the training of deep neural networks (DNN). In a typical data parallelism approach, the local workers push the latest updates of all the parameters to the parameter server and pull all merged parameters back periodically. However, with the increasing size of DNN models and the large number of workers in practice, this typical data parallelism cannot achieve satisfactory training acceleration, since it usually suffers from the heavy communication cost due to transferring huge amount of information between workers and the parameter server. In-depth understanding on DNN has revealed that it is usually highly redundant, that deleting a considerable proportion of the parameters will not significantly decline the model performance. This redundancy property exposes a great opportunity to reduce the communication cost by only transferring the information of those significant parameters during the parallel training. However, if we only transfer information of temporally significant parameters of the latest snapshot, we may miss the parameters that are insignificant now but have potential to become significant as the training process goes on. To this end, we design an Explore-Exploit framework to dynamically choose the subset to be communicated, which is comprised of the significant parameters in the latest snapshot together with a random explored set of other parameters. We propose to measure the significance of the parameter by the combination of its magnitude and gradient. Our experimental results demonstrate that our proposed Slim-DP can achieve better training acceleration than standard data parallelism and its communication-efficient version by saving communication time without loss of accuracy.