 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketch-based Video Object Segmentation: Benchmark and Analysis
Paper and Code

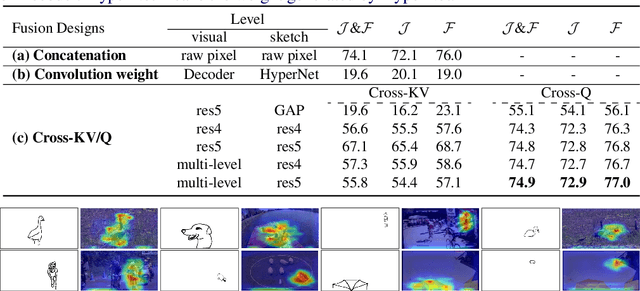

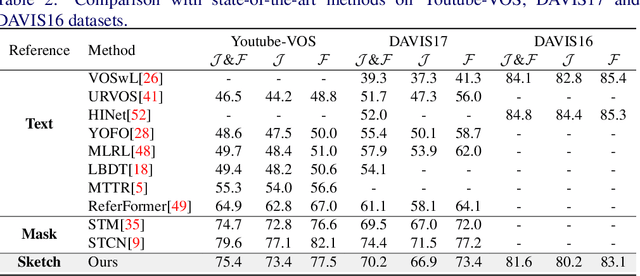
Reference-based video object segmentation is an emerging topic which aims to segment the corresponding target object in each video frame referred by a given reference, such as a language expression or a photo mask. However, language expressions can sometimes be vague in conveying an intended concept and ambiguous when similar objects in one frame are hard to distinguish by language. Meanwhile, photo masks are costly to annotate and less practical to provide in a real application. This paper introduces a new task of sketch-based video object segmentation, an associated benchmark, and a strong baseline. Our benchmark includes three datasets, Sketch-DAVIS16, Sketch-DAVIS17 and Sketch-YouTube-VOS, which exploit human-drawn sketches as an informative yet low-cost reference for video object segmentation. We take advantage of STCN, a popular baseline of semi-supervised VOS task, and evaluate what the most effective design for incorporating a sketch reference is. Experimental results show sketch is more effective yet annotation-efficient than other references, such as photo masks, language and scribble.