 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingMOS: An extensive Open-Source Singing Voice Dataset for MOS Prediction
Paper and Code
Jun 16, 2024

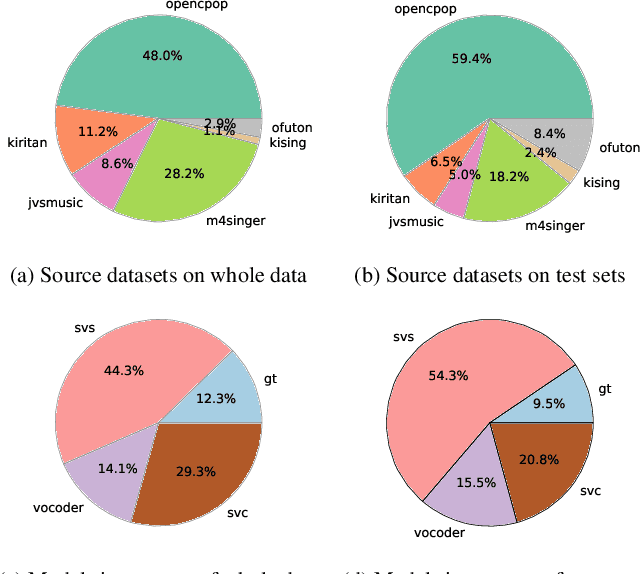

In speech generation tasks, human subjective ratings, usually referred to as the opinion score, are considered the "gold standard" for speech quality evaluation, with the mean opinion score (MOS) serving as the primary evaluation metric. Due to the high cost of human annotation, several MOS prediction systems have emerged in the speech domain, demonstrating good performance. These MOS prediction models are trained using annotations from previous speech-related challenges. However, compared to the speech domain, the singing domain faces data scarcity and stricter copyright protections, leading to a lack of high-quality MOS-annotated datasets for singing. To address this, we propose SingMOS, a high-quality and diverse MOS dataset for singing, covering a range of Chinese and Japanese datasets. These synthesized vocals are generated using state-of-the-art models in singing synthesis, conversion, or resynthesis tasks and are rated by professional annotators alongside real vocals. Data analysis demonstrates the diversity and reliability of our dataset. Additionally, we conduct further exploration on SingMOS, providing insights for singing MOS prediction and guidance for the continued expansion of SingMOS.