 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Mapping and Target Driven Navigation
Paper and Code
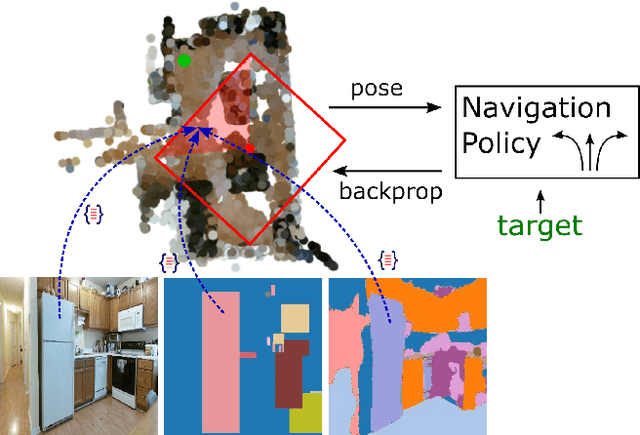
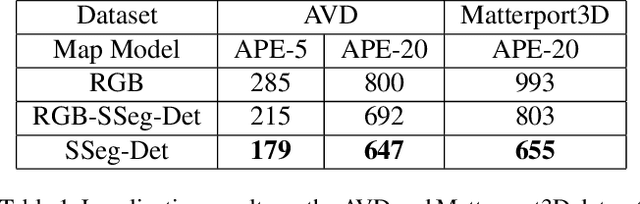
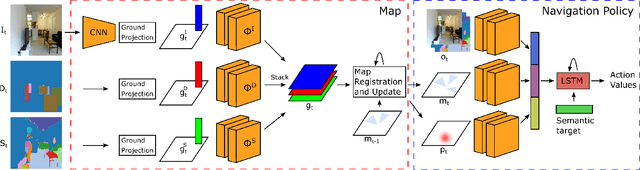

This work presents a modular architecture for simultaneous mapping and target driven navigation in indoors environments. The semantic and appearance stored in 2.5D map is distilled from RGB images, semantic segmentation and outputs of object detectors by convolutional neural networks. Given this representation, the mapping module learns to localize the agent and register consecutive observations in the map. The navigation task is then formulated as a problem of learning a policy for reaching semantic targets using current observations and the up-to-date map. We demonstrate that the use of semantic information improves localization accuracy and the ability of storing spatial semantic map aids the target driven navigation policy. The two modules are evaluated separately and jointly on Active Vision Dataset and Matterport3D environments, demonstrating improved performance on both localization and navigation tasks.