 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple and Effective VAE Training with Calibrated Decoders
Paper and Code



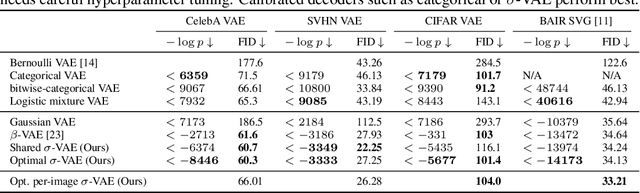
Variational autoencoders (VAEs) provide an effective and simple method for modeling complex distributions. However, training VAEs often requires considerable hyperparameter tuning, and often utilizes a heuristic weight on the prior KL-divergence term. In this work, we study how the performance of VAEs can be improved while not requiring the use of this heuristic hyperparameter, by learning calibrated decoders that accurately model the decoding distribution. While in some sense it may seem obvious that calibrated decoders should perform better than uncalibrated decoders, much of the recent literature that employs VAEs uses uncalibrated Gaussian decoders with constant variance. We observe empirically that the na\"{i}ve way of learning variance in Gaussian decoders does not lead to good results. However, {other calibrated decoders, such as discrete decoders or learning shared variance} can substantially improve performance. To further improve results, we propose a simple but novel modification to the commonly used Gaussian decoder, which represents the prediction variance non-parametrically. We observe empirically that using the heuristic weight hyperparameter is not necessary with our method. We analyze the performance of various discrete and continuous decoders on a range of datasets and several single-image and sequential VAE models. Project website: \url{https://orybkin.github.io/sigma-vae/}