 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimLM: Pre-training with Representation Bottleneck for Dense Passage Retrieval
Paper and Code



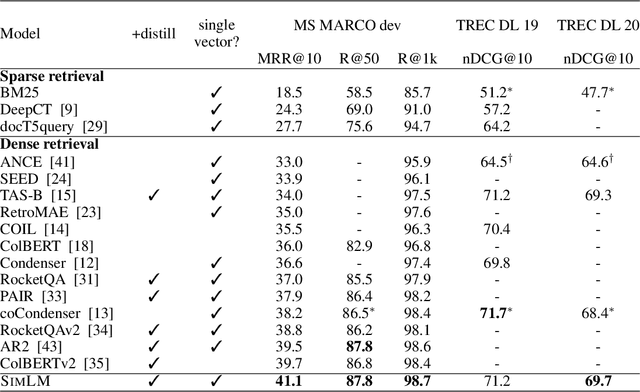
In this paper, we propose SimLM (Similarity matching with Language Model pre-training), a simple yet effective pre-training method for dense passage retrieval. It employs a simple bottleneck architecture that learns to compress the passage information into a dense vector through self-supervised pre-training. We use a replaced language modeling objective, which is inspired by ELECTRA, to improve the sample efficiency and reduce the mismatch of the input distribution between pre-training and fine-tuning. SimLM only requires access to unlabeled corpus, and is more broadly applicable when there are no labeled data or queries. We conduct experiments on several large-scale passage retrieval datasets, and show substantial improvements over strong baselines under various settings. Remarkably, SimLM even outperforms multi-vector approaches such as ColBERTv2 which incurs significantly more storage cost.