 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity Based Label Smoothing For Dialogue Generation
Paper and Code
Jul 23, 2021
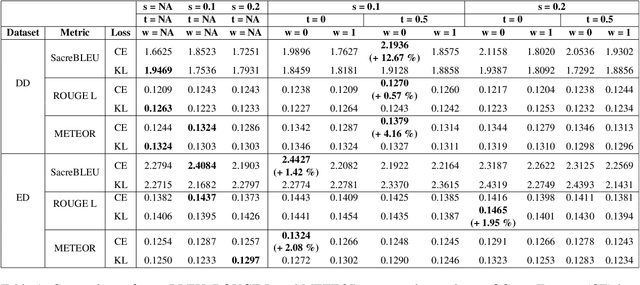
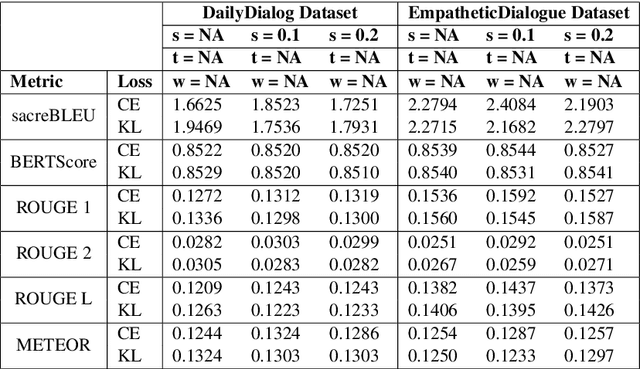
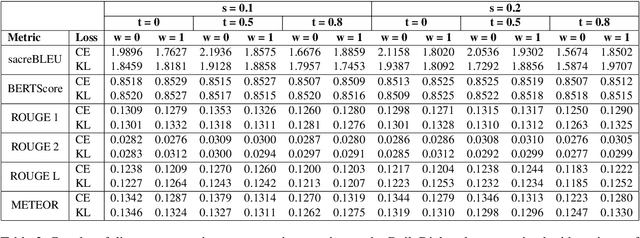
Generative neural conversational systems are generally trained with the objective of minimizing the entropy loss between the training "hard" targets and the predicted logits. Often, performance gains and improved generalization can be achieved by using regularization techniques like label smoothing, which converts the training "hard" targets to "soft" targets. However, label smoothing enforces a data independent uniform distribution on the incorrect training targets, which leads to an incorrect assumption of equi-probable incorrect targets for each correct target. In this paper we propose and experiment with incorporating data dependent word similarity based weighing methods to transforms the uniform distribution of the incorrect target probabilities in label smoothing, to a more natural distribution based on semantics. We introduce hyperparameters to control the incorrect target distribution, and report significant performance gains over networks trained using standard label smoothing based loss, on two standard open domain dialogue corpora.