 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharp global convergence guarantees for iterative nonconvex optimization: A Gaussian process perspective
Paper and Code
Sep 20, 2021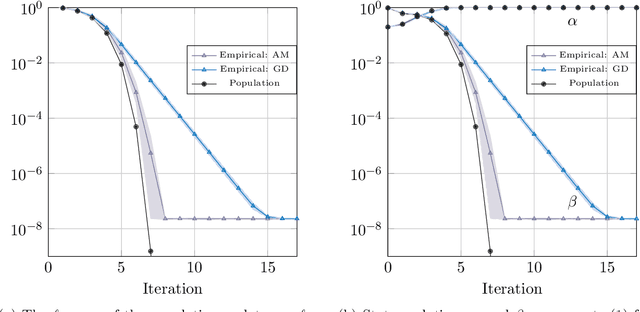

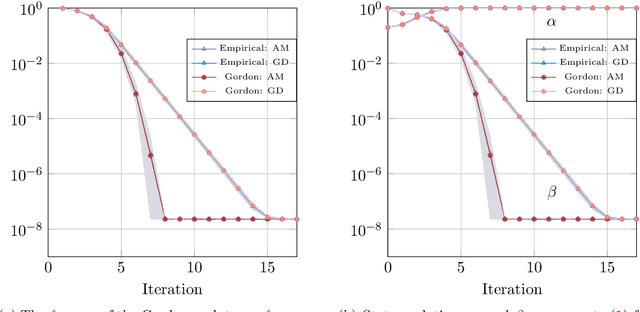
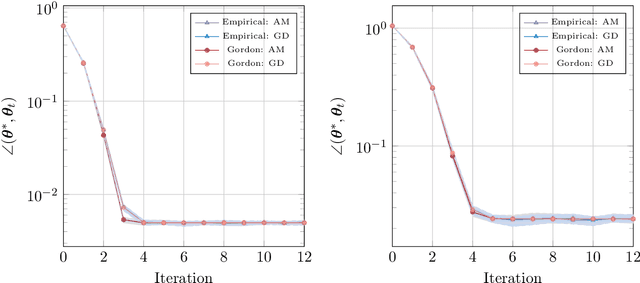
We consider a general class of regression models with normally distributed covariates, and the associated nonconvex problem of fitting these models from data. We develop a general recipe for analyzing the convergence of iterative algorithms for this task from a random initialization. In particular, provided each iteration can be written as the solution to a convex optimization problem satisfying some natural conditions, we leverage Gaussian comparison theorems to derive a deterministic sequence that provides sharp upper and lower bounds on the error of the algorithm with sample-splitting. Crucially, this deterministic sequence accurately captures both the convergence rate of the algorithm and the eventual error floor in the finite-sample regime, and is distinct from the commonly used "population" sequence that results from taking the infinite-sample limit. We apply our general framework to derive several concrete consequences for parameter estimation in popular statistical models including phase retrieval and mixtures of regressions. Provided the sample size scales near-linearly in the dimension, we show sharp global convergence rates for both higher-order algorithms based on alternating updates and first-order algorithms based on subgradient descent. These corollaries, in turn, yield multiple consequences, including: (a) Proof that higher-order algorithms can converge significantly faster than their first-order counterparts (and sometimes super-linearly), even if the two share the same population update and (b) Intricacies in super-linear convergence behavior for higher-order algorithms, which can be nonstandard (e.g., with exponent 3/2) and sensitive to the noise level in the problem. We complement these results with extensive numerical experiments, which show excellent agreement with our theoretical predictions.