 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSet-Valued Shadow Matching Using Zonotopes for 3-D Map-Aided GNSS Localization
Paper and Code
Sep 28, 2022


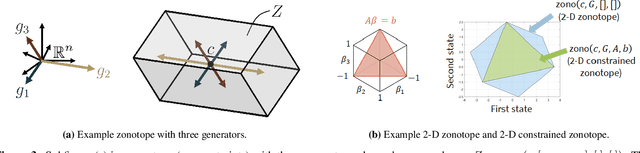
Unlike many urban localization methods that return point-valued estimates, a set-valued representation enables robustness by ensuring that a continuum of possible positions obeys safety constraints. One strategy with the potential for set-valued estimation is GNSS-based shadow matching~(SM), where one uses a three-dimensional (3-D) map to compute GNSS shadows (where line-of-sight is blocked). However, SM requires a point-valued grid for computational tractability, with accuracy limited by grid resolution. We propose zonotope shadow matching (ZSM) for set-valued 3-D map-aided GNSS localization. ZSM represents buildings and GNSS shadows using constrained zonotopes, a convex polytope representation that enables propagating set-valued estimates using fast vector concatenation operations. Starting from a coarse set-valued position, ZSM refines the estimate depending on the receiver being inside or outside each shadow as judged by received carrier-to-noise density. We demonstrated our algorithm's performance using simulated experiments on a simple 3-D example map and on a dense 3-D map of San Francisco.