 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSerial Contrastive Knowledge Distillation for Continual Few-shot Relation Extraction
Paper and Code
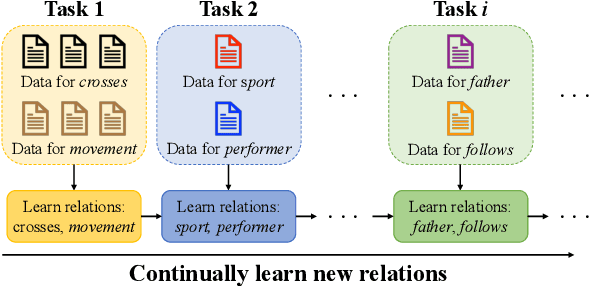
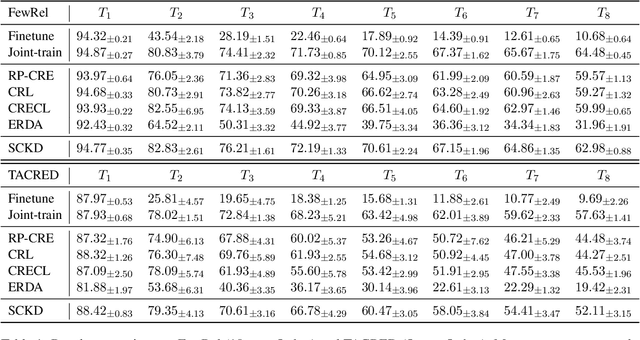
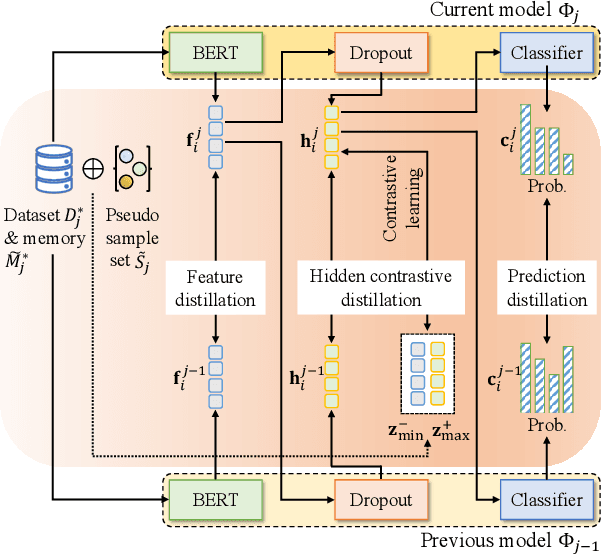
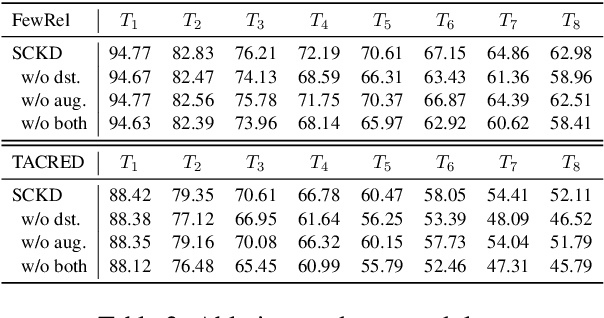
Continual few-shot relation extraction (RE) aims to continuously train a model for new relations with few labeled training data, of which the major challenges are the catastrophic forgetting of old relations and the overfitting caused by data sparsity. In this paper, we propose a new model, namely SCKD, to accomplish the continual few-shot RE task. Specifically, we design serial knowledge distillation to preserve the prior knowledge from previous models and conduct contrastive learning with pseudo samples to keep the representations of samples in different relations sufficiently distinguishable. Our experiments on two benchmark datasets validate the effectiveness of SCKD for continual few-shot RE and its superiority in knowledge transfer and memory utilization over state-of-the-art models.