 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence Parallelism: Long Sequence Training from System Perspective
Paper and Code
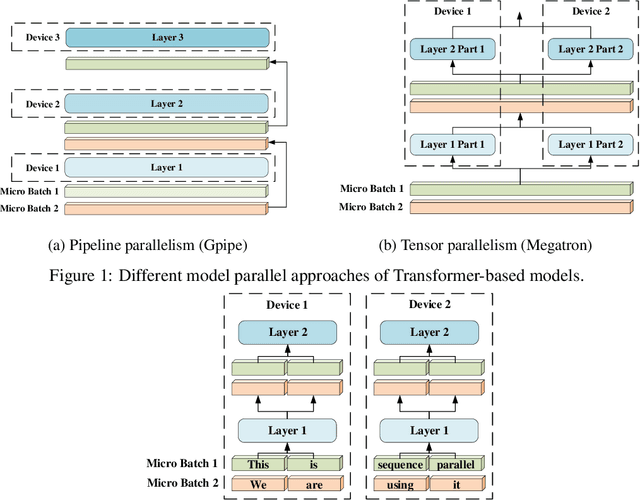


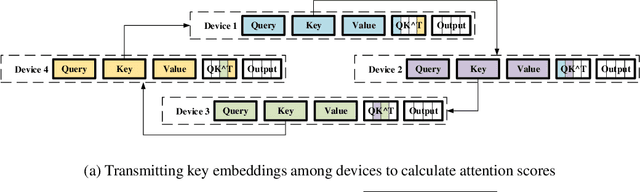
Within Transformer, self-attention is the key module to learn powerful context-aware representations. However, self-attention suffers from quadratic memory requirements with respect to the sequence length, which limits us to process longer sequence on GPU. In this work, we propose sequence parallelism, a memory efficient parallelism method to help us break input sequence length limitation and train with longer sequence on GPUs. Compared with existing parallelism, our approach no longer requires a single device to hold the whole sequence. Specifically, we split the input sequence into multiple chunks and feed each chunk into its corresponding device (i.e. GPU). To compute the attention output, we communicate attention embeddings among GPUs. Inspired by ring all-reduce, we integrated ring-style communication with self-attention calculation and proposed Ring Self-Attention (RSA). Our implementation is fully based on PyTorch. Without extra compiler or library changes, our approach is compatible with data parallelism and pipeline parallelism. Experiments show that sequence parallelism performs well when scaling with batch size and sequence length. Compared with tensor parallelism, our approach achieved $13.7\times$ and $3.0\times$ maximum batch size and sequence length respectively when scaling up to 64 NVIDIA P100 GPUs. We plan to integrate our sequence parallelism with data, pipeline and tensor parallelism to further train large-scale models with 4D parallelism in our future work.