 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeq2Seq2Sentiment: Multimodal Sequence to Sequence Models for Sentiment Analysis
Paper and Code
Aug 06, 2018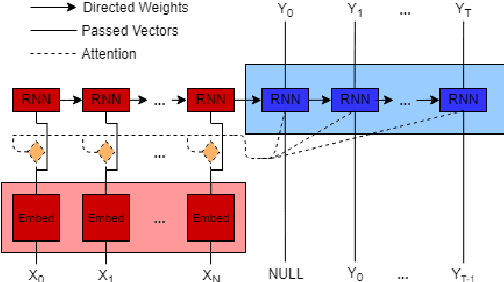

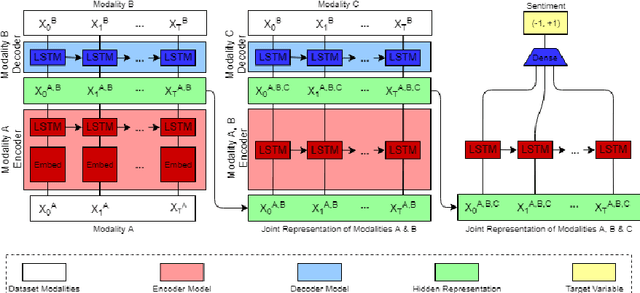

Multimodal machine learning is a core research area spanning the language, visual and acoustic modalities. The central challenge in multimodal learning involves learning representations that can process and relate information from multiple modalities. In this paper, we propose two methods for unsupervised learning of joint multimodal representations using sequence to sequence (Seq2Seq) methods: a \textit{Seq2Seq Modality Translation Model} and a \textit{Hierarchical Seq2Seq Modality Translation Model}. We also explore multiple different variations on the multimodal inputs and outputs of these seq2seq models. Our experiments on multimodal sentiment analysis using the CMU-MOSI dataset indicate that our methods learn informative multimodal representations that outperform the baselines and achieve improved performance on multimodal sentiment analysis, specifically in the Bimodal case where our model is able to improve F1 Score by twelve points. We also discuss future directions for multimodal Seq2Seq methods.