Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparating Invisible Sounds Toward Universal Audiovisual Scene-Aware Sound Separation
Paper and Code
Oct 18, 2023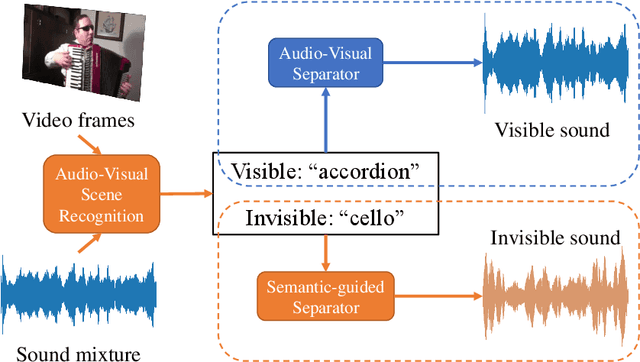

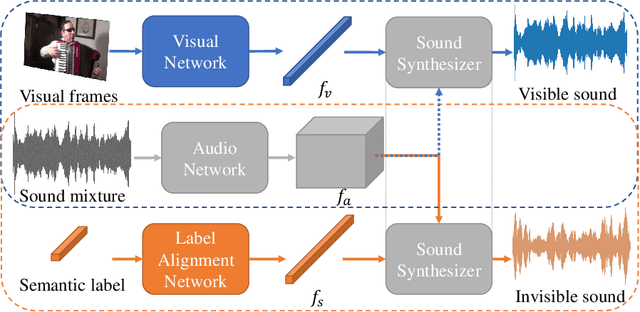
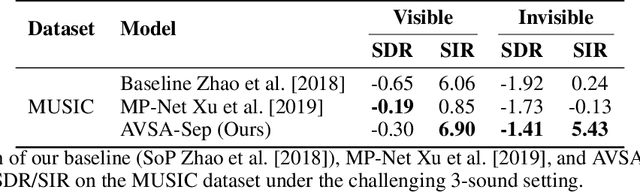
The audio-visual sound separation field assumes visible sources in videos, but this excludes invisible sounds beyond the camera's view. Current methods struggle with such sounds lacking visible cues. This paper introduces a novel "Audio-Visual Scene-Aware Separation" (AVSA-Sep) framework. It includes a semantic parser for visible and invisible sounds and a separator for scene-informed separation. AVSA-Sep successfully separates both sound types, with joint training and cross-modal alignment enhancing effectiveness.
* Accepted at ICCV 2023 - AV4D, 4 figures, 3 tables
View paper on