 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence Alignment with Parallel Documents Helps Biomedical Machine Translation
Paper and Code
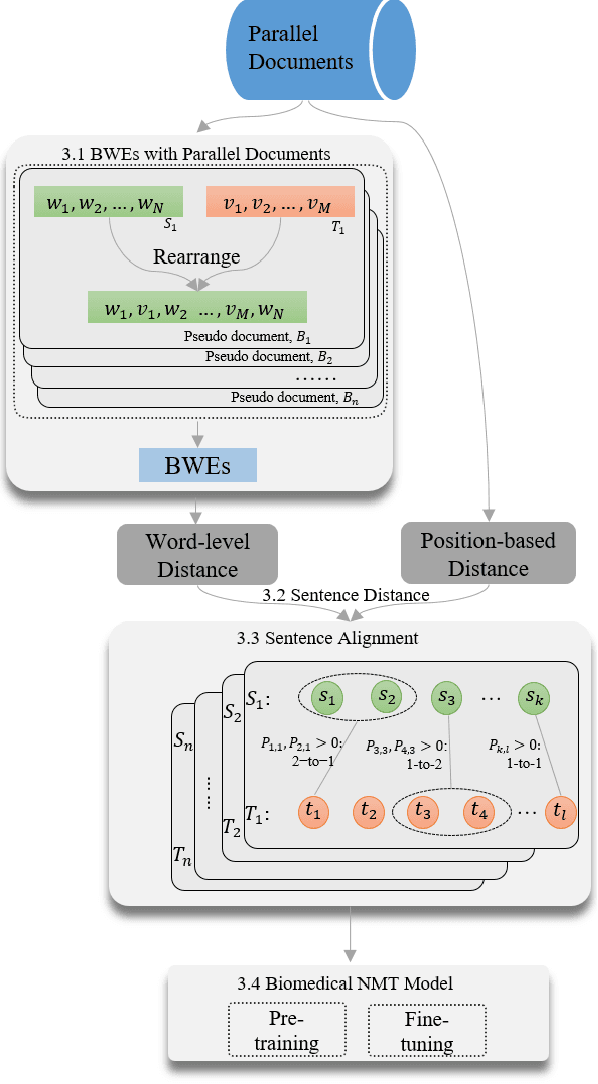
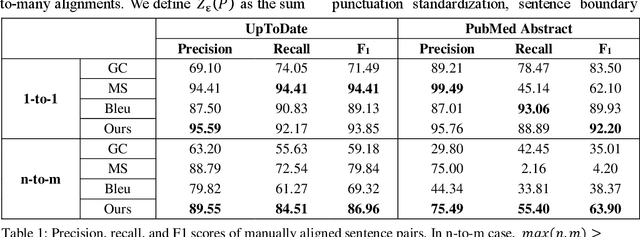
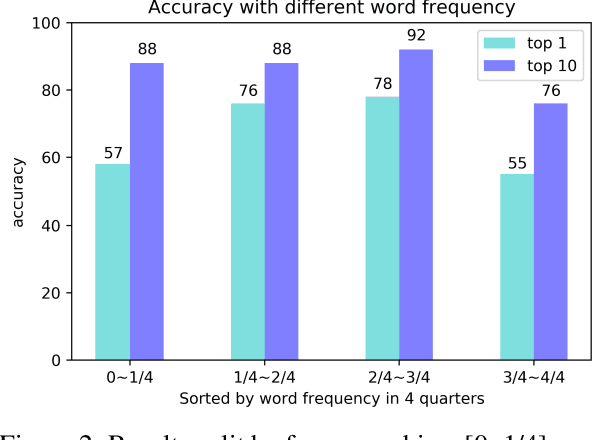
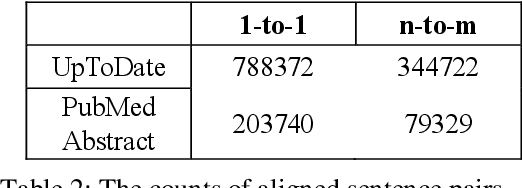
The existing neural machine translation system has achieved near human-level performance in general domain in some languages, but the lack of parallel corpora poses a key problem in specific domains. In biomedical domain, the parallel corpus is less accessible. This work presents a new unsupervised sentence alignment method and explores features in training biomedical neural machine translation (NMT) systems. We use a simple but effective way to build bilingual word embeddings (BWEs) to evaluate bilingual word similarity and transferred the sentence alignment problem into an extended earth mover's distance (EMD) problem. The proposed method achieved high accuracy in both 1-to-1 and many-to-many cases. Pre-training in general domain, the larger in-domain dataset and n-to-m sentence pairs benefit the NMT model. Fine-tuning in domain corpus helps the translation model learns more terminology and fits the in-domain style of text.