 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEN12MS -- A Curated Dataset of Georeferenced Multi-Spectral Sentinel-1/2 Imagery for Deep Learning and Data Fusion
Paper and Code
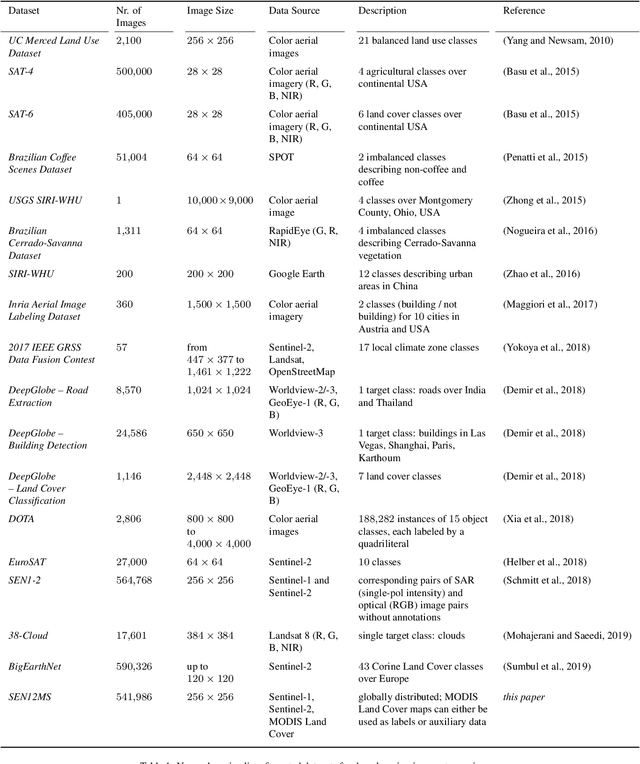
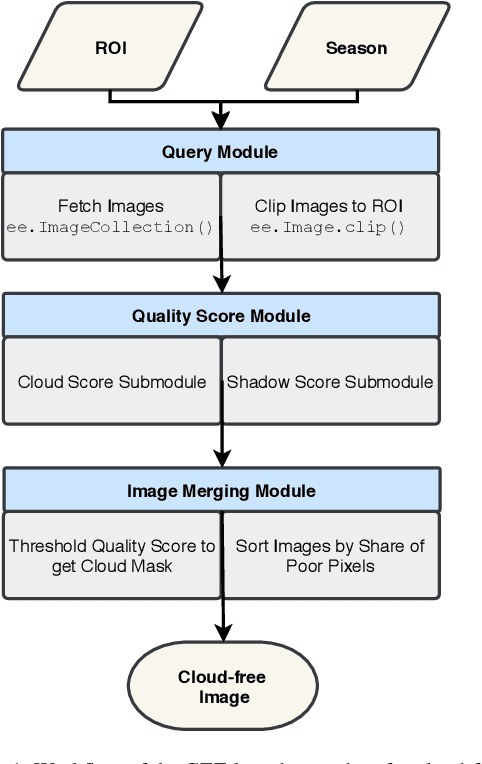
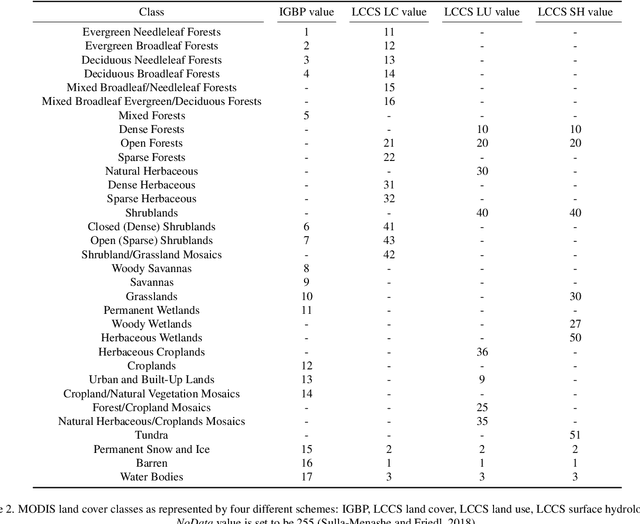

The availability of curated large-scale training data is a crucial factor for the development of well-generalizing deep learning methods for the extraction of geoinformation from multi-sensor remote sensing imagery. While quite some datasets have already been published by the community, most of them suffer from rather strong limitations, e.g. regarding spatial coverage, diversity or simply number of available samples. Exploiting the freely available data acquired by the Sentinel satellites of the Copernicus program implemented by the European Space Agency, as well as the cloud computing facilities of Google Earth Engine, we provide a dataset consisting of 180,662 triplets of dual-pol synthetic aperture radar (SAR) image patches, multi-spectral Sentinel-2 image patches, and MODIS land cover maps. With all patches being fully georeferenced at a 10 m ground sampling distance and covering all inhabited continents during all meteorological seasons, we expect the dataset to support the community in developing sophisticated deep learning-based approaches for common tasks such as scene classification or semantic segmentation for land cover mapping.