 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Learning Enabled by Multiscale Deep Neural Network Inversion
Paper and Code
Feb 27, 2018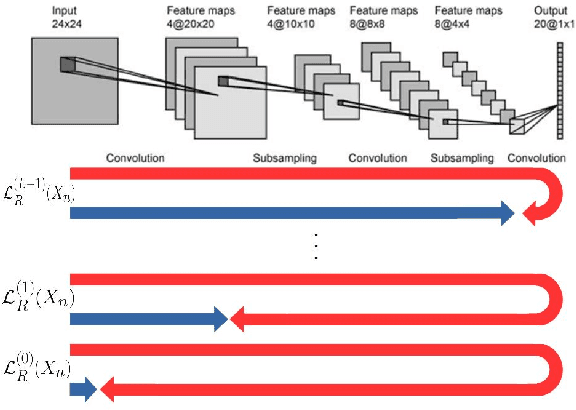
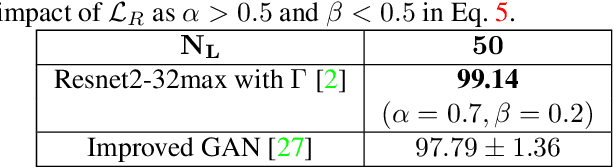
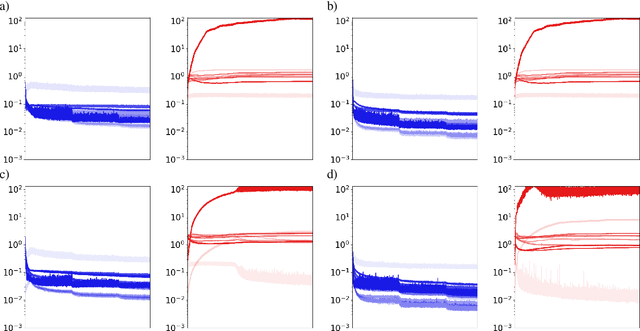
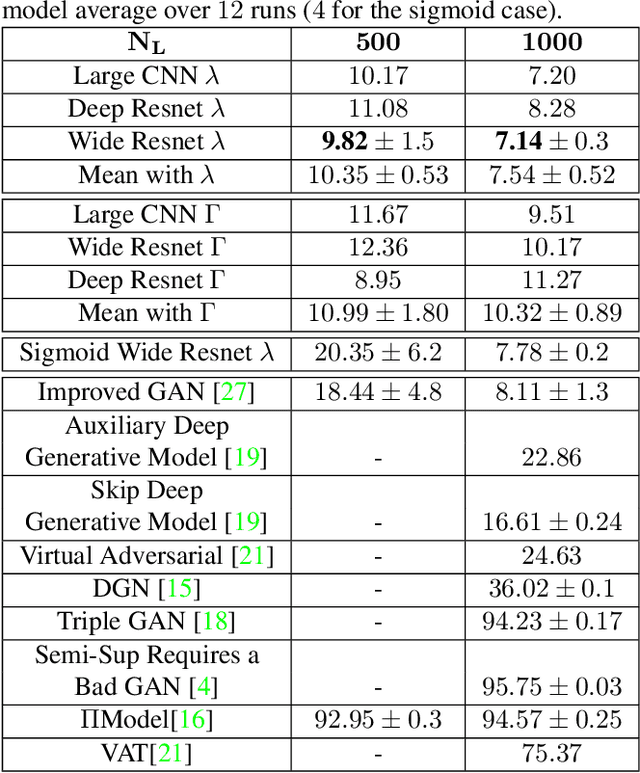
Deep Neural Networks (DNNs) provide state-of-the-art solutions in several difficult machine perceptual tasks. However, their performance relies on the availability of a large set of labeled training data, which limits the breadth of their applicability. Hence, there is a need for new {\em semi-supervised learning} methods for DNNs that can leverage both (a small amount of) labeled and unlabeled training data. In this paper, we develop a general loss function enabling DNNs of any topology to be trained in a semi-supervised manner without extra hyper-parameters. As opposed to current semi-supervised techniques based on topology-specific or unstable approaches, ours is both robust and general. We demonstrate that our approach reaches state-of-the-art performance on the SVHN ($9.82\%$ test error, with $500$ labels and wide Resnet) and CIFAR10 (16.38% test error, with 8000 labels and sigmoid convolutional neural network) data sets.