 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantics-Oriented Multitask Learning for DeepFake Detection: A Joint Embedding Approach
Paper and Code
Aug 29, 2024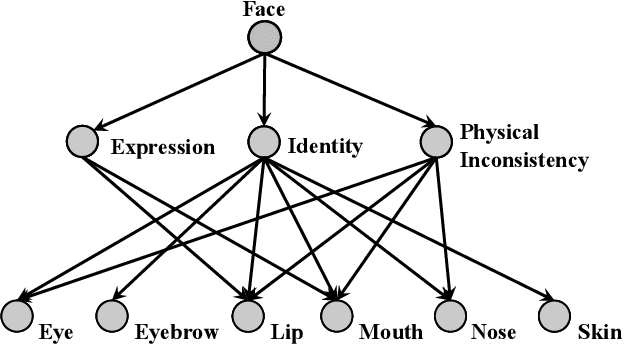
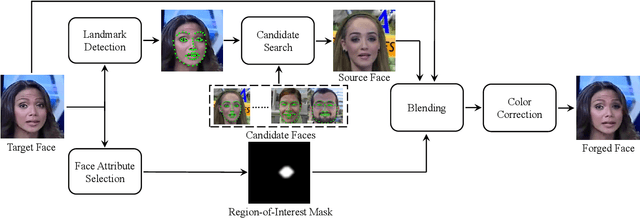
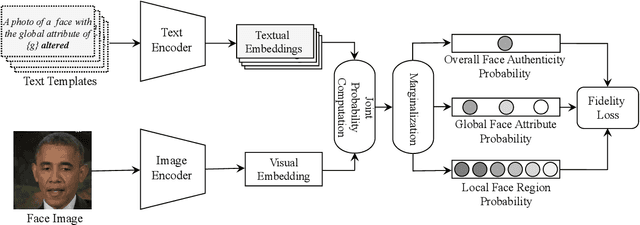
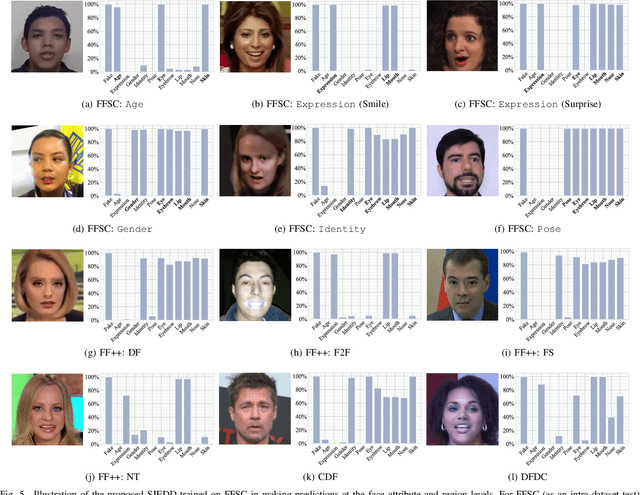
In recent years, the multimedia forensics and security community has seen remarkable progress in multitask learning for DeepFake (i.e., face forgery) detection. The prevailing strategy has been to frame DeepFake detection as a binary classification problem augmented by manipulation-oriented auxiliary tasks. This strategy focuses on learning features specific to face manipulations, which exhibit limited generalizability. In this paper, we delve deeper into semantics-oriented multitask learning for DeepFake detection, leveraging the relationships among face semantics via joint embedding. We first propose an automatic dataset expansion technique that broadens current face forgery datasets to support semantics-oriented DeepFake detection tasks at both the global face attribute and local face region levels. Furthermore, we resort to joint embedding of face images and their corresponding labels (depicted by textual descriptions) for prediction. This approach eliminates the need for manually setting task-agnostic and task-specific parameters typically required when predicting labels directly from images. In addition, we employ a bi-level optimization strategy to dynamically balance the fidelity loss weightings of various tasks, making the training process fully automated. Extensive experiments on six DeepFake datasets show that our method improves the generalizability of DeepFake detection and, meanwhile, renders some degree of model interpretation by providing human-understandable explanations.