 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically Distributed Robust Optimization for Vision-and-Language Inference
Paper and Code

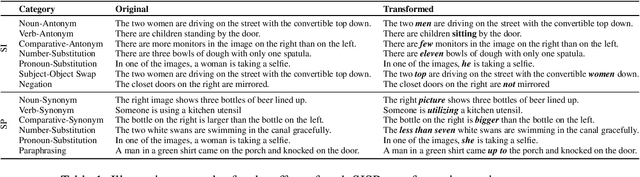
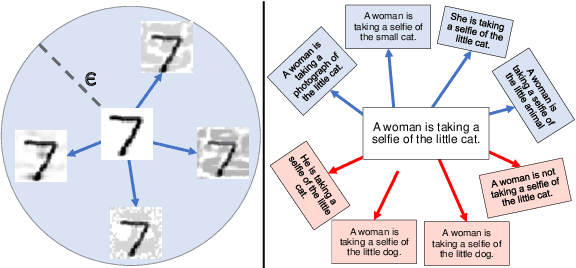
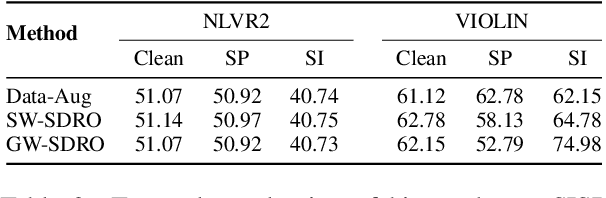
Analysis of vision-and-language models has revealed their brittleness under linguistic phenomena such as paraphrasing, negation, textual entailment, and word substitutions with synonyms or antonyms. While data augmentation techniques have been designed to mitigate against these failure modes, methods that can integrate this knowledge into the training pipeline remain under-explored. In this paper, we present \textbf{SDRO}, a model-agnostic method that utilizes a set linguistic transformations in a distributed robust optimization setting, along with an ensembling technique to leverage these transformations during inference. Experiments on benchmark datasets with images (NLVR$^2$) and video (VIOLIN) demonstrate performance improvements as well as robustness to adversarial attacks. Experiments on binary VQA explore the generalizability of this method to other V\&L tasks.