 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Image Synthesis for Abdominal CT
Paper and Code
Dec 11, 2023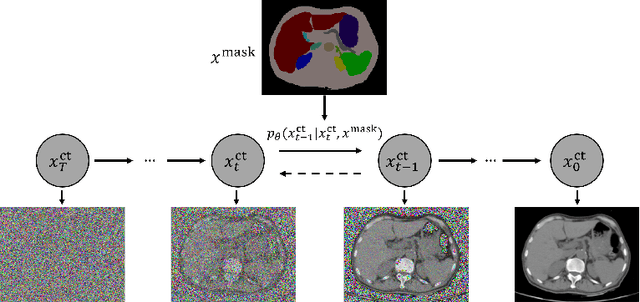
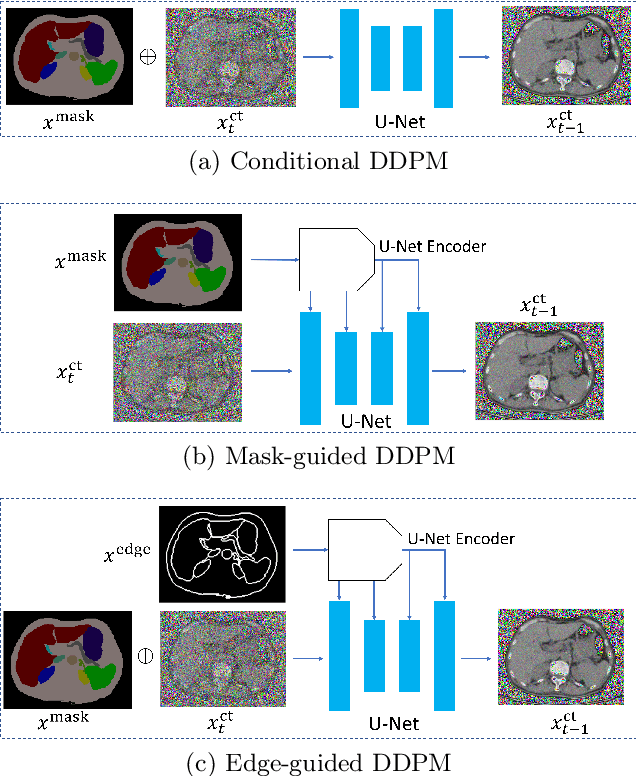
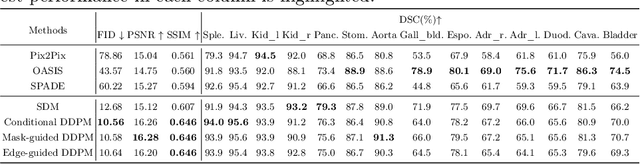
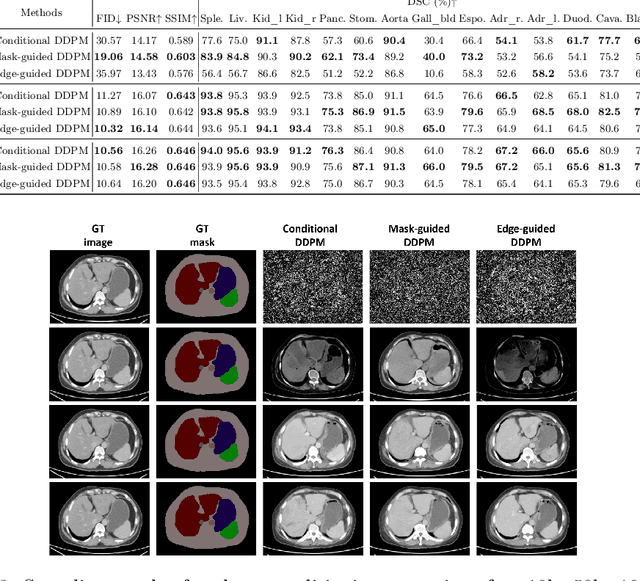
As a new emerging and promising type of generative models, diffusion models have proven to outperform Generative Adversarial Networks (GANs) in multiple tasks, including image synthesis. In this work, we explore semantic image synthesis for abdominal CT using conditional diffusion models, which can be used for downstream applications such as data augmentation. We systematically evaluated the performance of three diffusion models, as well as to other state-of-the-art GAN-based approaches, and studied the different conditioning scenarios for the semantic mask. Experimental results demonstrated that diffusion models were able to synthesize abdominal CT images with better quality. Additionally, encoding the mask and the input separately is more effective than na\"ive concatenating.