 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Training Vision Language BERTs with a Unified Conditional Model
Paper and Code
Jan 06, 2022
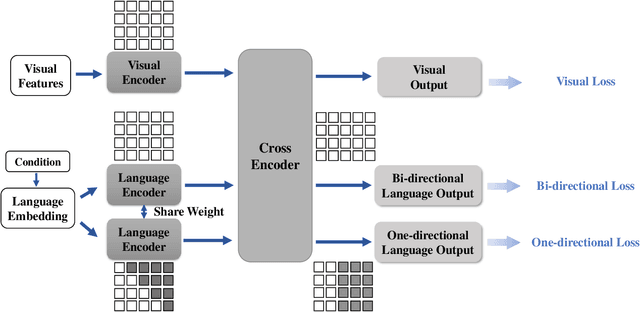
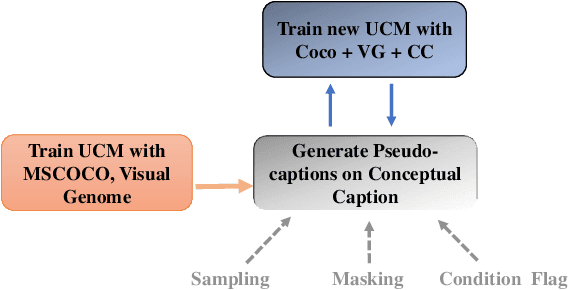

Natural language BERTs are trained with language corpus in a self-supervised manner. Unlike natural language BERTs, vision language BERTs need paired data to train, which restricts the scale of VL-BERT pretraining. We propose a self-training approach that allows training VL-BERTs from unlabeled image data. The proposed method starts with our unified conditional model -- a vision language BERT model that can perform zero-shot conditional generation. Given different conditions, the unified conditional model can generate captions, dense captions, and even questions. We use the labeled image data to train a teacher model and use the trained model to generate pseudo captions on unlabeled image data. We then combine the labeled data and pseudo labeled data to train a student model. The process is iterated by putting the student model as a new teacher. By using the proposed self-training approach and only 300k unlabeled extra data, we are able to get competitive or even better performances compared to the models of similar model size trained with 3 million extra image data.