 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Training of Graph Convolutional Networks
Paper and Code
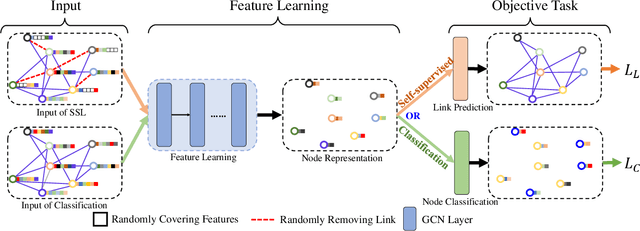
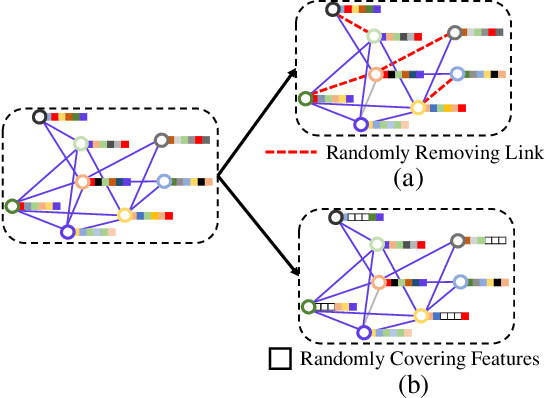
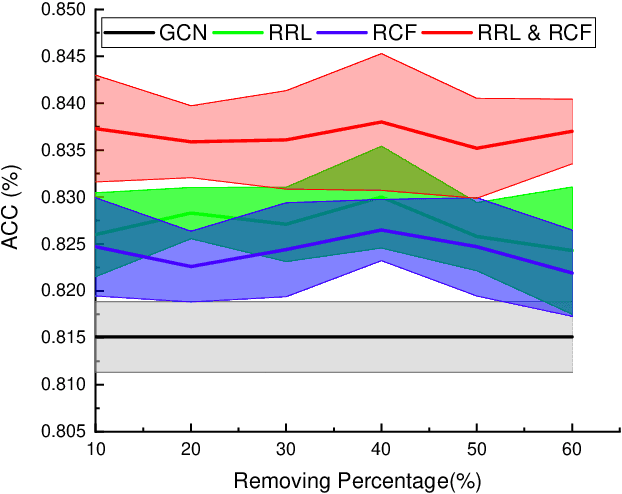

Graph Convolutional Networks (GCNs) have been successfully applied to analyze non-grid data, where the classical convolutional neural networks (CNNs) cannot be directly used. One similarity shared by GCNs and CNNs is the requirement of massive amount of labeled data for network training. In addition, GCNs need the adjacency matrix as input to define the relationship between those non-grid data, which leads to all of data including training, validation and test data typically forms only one graph structures data for training. Furthermore, the adjacency matrix is usually pre-defined and stationary, which makes the data augmentation strategies cannot be employed on the constructed graph structures data to augment the amount of training data. To further improve the learning capacity and model performance under the limited training data, in this paper, we propose two types of self-supervised learning strategies to exploit available information from the input graph structure data itself. Our proposed self-supervised learning strategies are examined on two representative GCN models with three public citation network datasets - Citeseer, Cora and Pubmed. The experimental results demonstrate the generalization ability as well as the portability of our proposed strategies, which can significantly improve the performance of GCNs with the power of self-supervised learning in improving feature learning.