 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Representation Learning for Detection of ACL Tear Injury in Knee MRI
Paper and Code
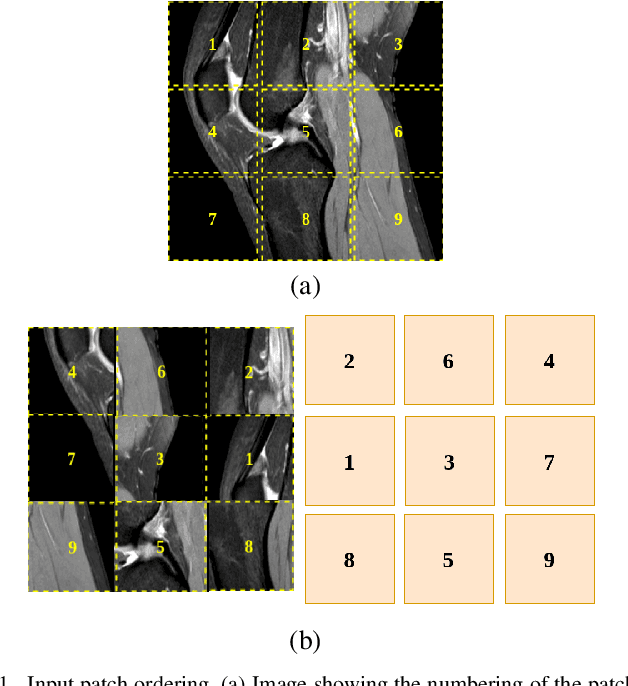


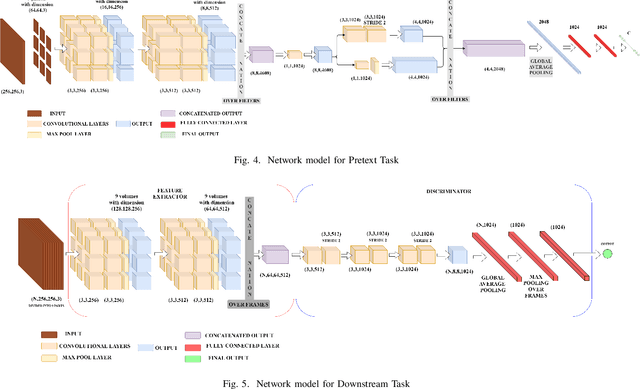
The success and efficiency of Deep Learning based models for computer vision applications require large scale human annotated data which are often expensive to generate. Self-supervised learning, a subset of unsupervised learning, handles this problem by learning meaningful features from unlabeled image or video data. In this paper, we propose a self-supervised learning approach to learn transferable features from MRI clips by enforcing the model to learn anatomical features. The pretext task models are designed to predict the correct ordering of the jumbled image patches that the MRI frames are divided into. To the best of our knowledge, none of the supervised learning models performing injury classification task from MRI frames, provide any explanations for the decisions made by the models, making our work the first of its kind on MRI data. Experiments on the pretext task show that this proposed approach enables the model to learn spatial context invariant features which helps in reliable and explainable performance in downstream tasks like classification of ACL tear injury from knee MRI. The efficiency of the novel Convolutional Neural Network proposed in this paper is reflected in the experimental results obtained in the downstream task.