 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Feature Enhancement: Applying Internal Pretext Task to Supervised Learning
Paper and Code
Jun 09, 2021
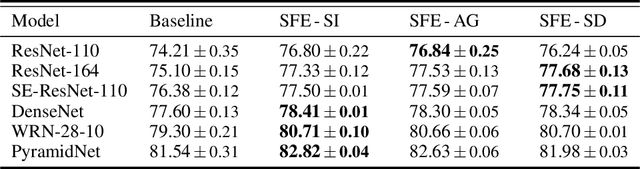


Traditional self-supervised learning requires CNNs using external pretext tasks (i.e., image- or video-based tasks) to encode high-level semantic visual representations. In this paper, we show that feature transformations within CNNs can also be regarded as supervisory signals to construct the self-supervised task, called \emph{internal pretext task}. And such a task can be applied for the enhancement of supervised learning. Specifically, we first transform the internal feature maps by discarding different channels, and then define an additional internal pretext task to identify the discarded channels. CNNs are trained to predict the joint labels generated by the combination of self-supervised labels and original labels. By doing so, we let CNNs know which channels are missing while classifying in the hope to mine richer feature information. Extensive experiments show that our approach is effective on various models and datasets. And it's worth noting that we only incur negligible computational overhead. Furthermore, our approach can also be compatible with other methods to get better results.