 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Labeling of Fully Mediating Representations by Graph Alignment
Paper and Code
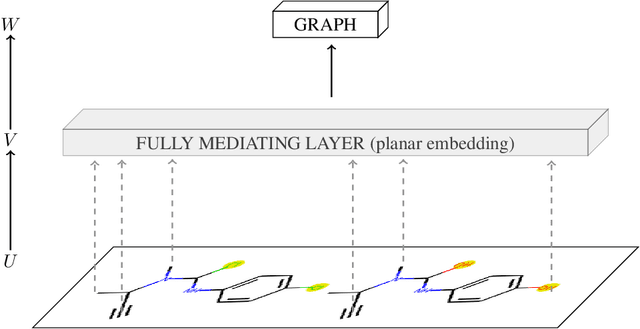

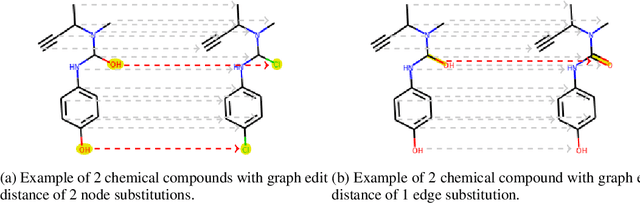
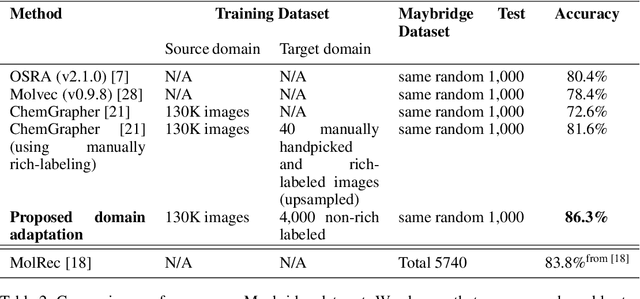
To be able to predict a molecular graph structure ($W$) given a 2D image of a chemical compound ($U$) is a challenging problem in machine learning. We are interested to learn $f: U \rightarrow W$ where we have a fully mediating representation $V$ such that $f$ factors into $U \rightarrow V \rightarrow W$. However, observing V requires detailed and expensive labels. We propose graph aligning approach that generates rich or detailed labels given normal labels $W$. In this paper we investigate the scenario of domain adaptation from the source domain where we have access to the expensive labels $V$ to the target domain where only normal labels W are available. Focusing on the problem of predicting chemical compound graphs from 2D images the fully mediating layer is represented using the planar embedding of the chemical graph structure we are predicting. The use of a fully mediating layer implies some assumptions on the mechanism of the underlying process. However if the assumptions are correct it should allow the machine learning model to be more interpretable, generalize better and be more data efficient at training time. The empirical results show that, using only 4000 data points, we obtain up to 4x improvement of performance after domain adaptation to target domain compared to pretrained model only on the source domain. After domain adaptation, the model is even able to detect atom types that were never seen in the original source domain. Finally, on the Maybridge data set the proposed self-labeling approach reached higher performance than the current state of the art.