Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Bounding Majority Vote Learning Algorithms by the Direct Minimization of a Tight PAC-Bayesian C-Bound
Paper and Code
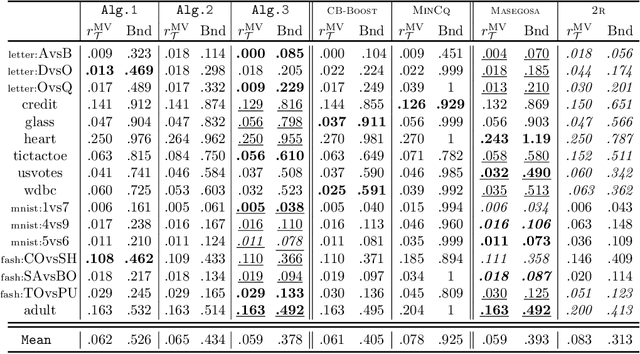
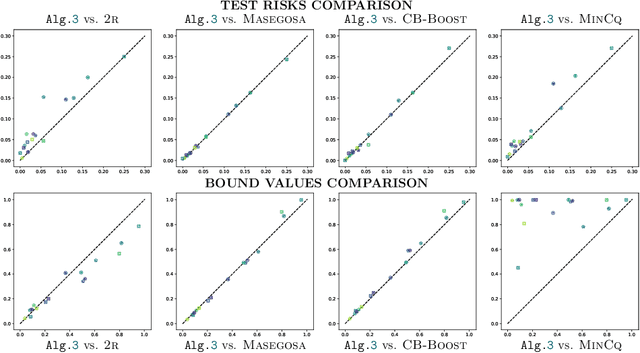

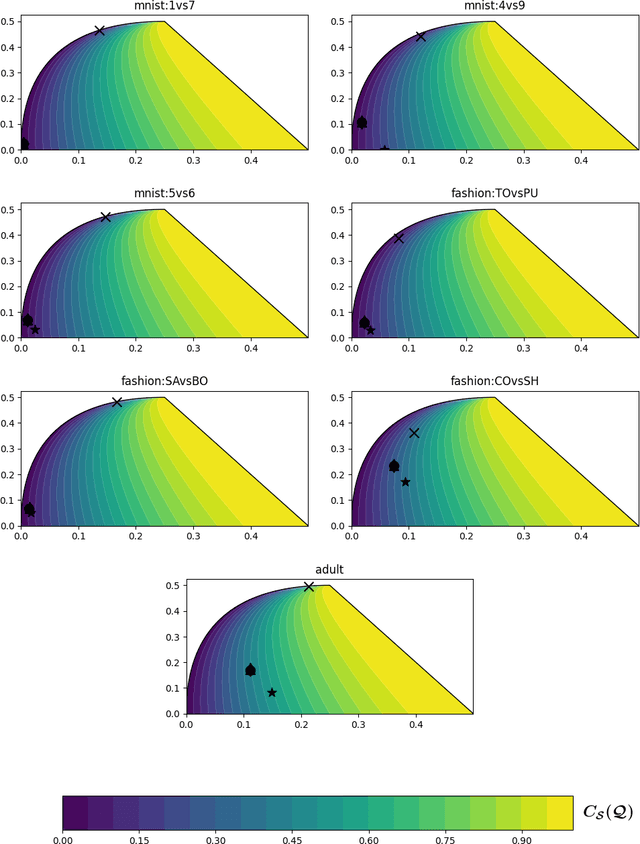
In the PAC-Bayesian literature, the C-Bound refers to an insightful relation between the risk of a majority vote classifier (under the zero-one loss) and the first two moments of its margin (i.e., the expected margin and the voters' diversity). Until now, learning algorithms developed in this framework minimize the empirical version of the C-Bound, instead of explicit PAC-Bayesian generalization bounds. In this paper, by directly optimizing PAC-Bayesian guarantees on the C-Bound, we derive self-bounding majority vote learning algorithms. Moreover, our algorithms based on gradient descent are scalable and lead to accurate predictors paired with non-vacuous guarantees.
View paper on