 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-attention with Functional Time Representation Learning
Paper and Code
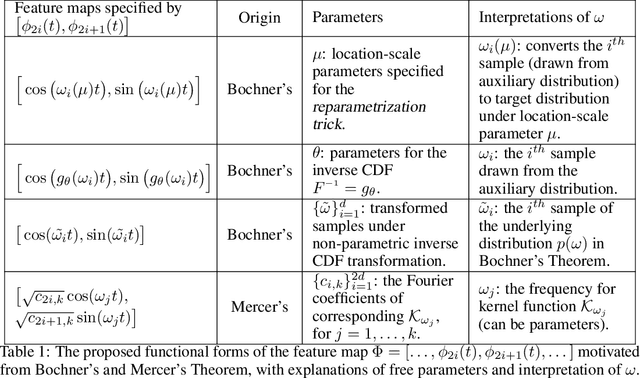
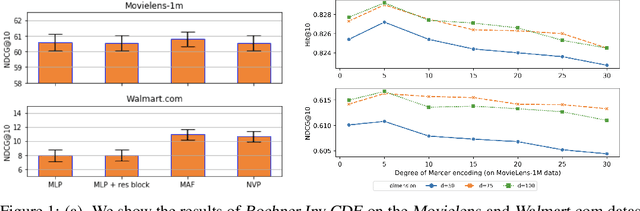
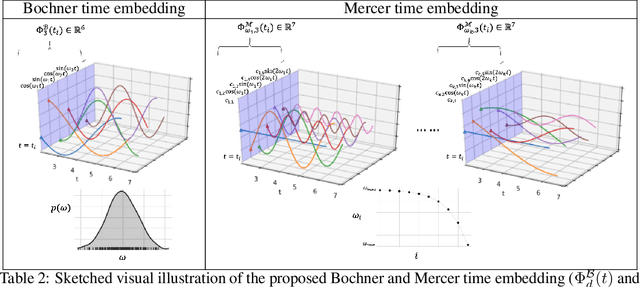
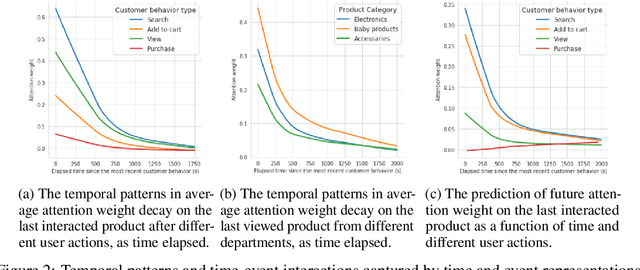
Sequential modelling with self-attention has achieved cutting edge performances in natural language processing. With advantages in model flexibility, computation complexity and interpretability, self-attention is gradually becoming a key component in event sequence models. However, like most other sequence models, self-attention does not account for the time span between events and thus captures sequential signals rather than temporal patterns. Without relying on recurrent network structures, self-attention recognizes event orderings via positional encoding. To bridge the gap between modelling time-independent and time-dependent event sequence, we introduce a functional feature map that embeds time span into high-dimensional spaces. By constructing the associated translation-invariant time kernel function, we reveal the functional forms of the feature map under classic functional function analysis results, namely Bochner's Theorem and Mercer's Theorem. We propose several models to learn the functional time representation and the interactions with event representation. These methods are evaluated on real-world datasets under various continuous-time event sequence prediction tasks. The experiments reveal that the proposed methods compare favorably to baseline models while also capturing useful time-event interactions.