 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Kernel Attention for Robust Speaker Verification
Paper and Code
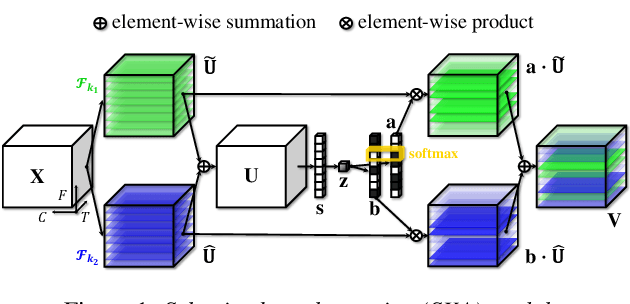
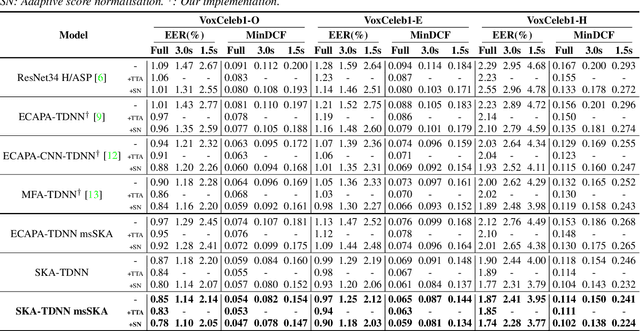

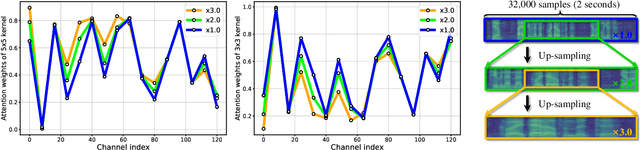
Recent state-of-the-art speaker verification architectures adopt multi-scale processing and frequency-channel attention techniques. However, their full potential may not have been exploited because these techniques' receptive fields are fixed where most convolutional layers operate with specified kernel sizes such as 1, 3 or 5. We aim to further improve this line of research by introducing a selective kernel attention (SKA) mechanism. The SKA mechanism allows each convolutional layer to adaptively select the kernel size in a data-driven fashion based on an attention mechanism that exploits both frequency and channel domain using the previous layer's output. We propose three module variants using the SKA mechanism whereby two modules are applied in front of an ECAPA-TDNN model, and the other is combined with the Res2Net backbone block. Experimental results demonstrate that our proposed model consistently outperforms the conventional counterpart on the three different evaluation protocols in terms of both equal error rate and minimum detection cost function. In addition, we present a detailed analysis that helps understand how the SKA module works.