 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelect-Additive Learning: Improving Generalization in Multimodal Sentiment Analysis
Paper and Code

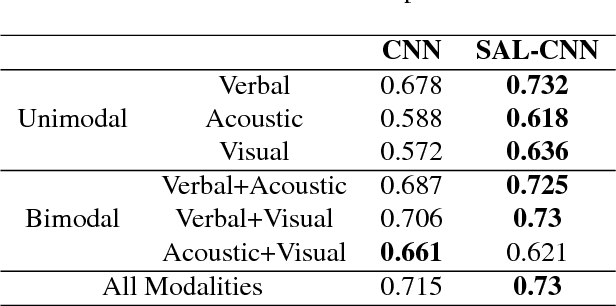
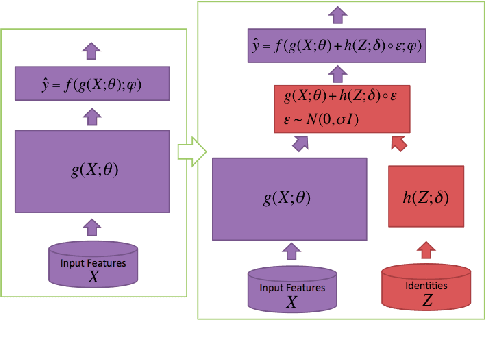
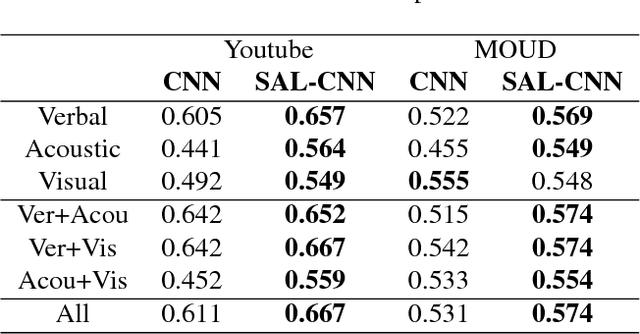
Multimodal sentiment analysis is drawing an increasing amount of attention these days. It enables mining of opinions in video reviews which are now available aplenty on online platforms. However, multimodal sentiment analysis has only a few high-quality data sets annotated for training machine learning algorithms. These limited resources restrict the generalizability of models, where, for example, the unique characteristics of a few speakers (e.g., wearing glasses) may become a confounding factor for the sentiment classification task. In this paper, we propose a Select-Additive Learning (SAL) procedure that improves the generalizability of trained neural networks for multimodal sentiment analysis. In our experiments, we show that our SAL approach improves prediction accuracy significantly in all three modalities (verbal, acoustic, visual), as well as in their fusion. Our results show that SAL, even when trained on one dataset, achieves good generalization across two new test datasets.