 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmental Spatiotemporal CNNs for Fine-grained Action Segmentation
Paper and Code
Sep 30, 2016

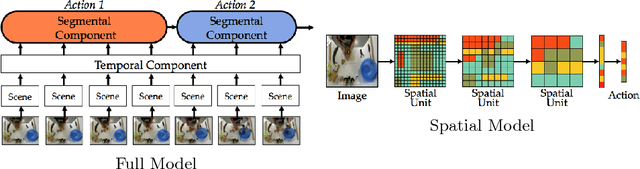

Joint segmentation and classification of fine-grained actions is important for applications of human-robot interaction, video surveillance, and human skill evaluation. However, despite substantial recent progress in large-scale action classification, the performance of state-of-the-art fine-grained action recognition approaches remains low. We propose a model for action segmentation which combines low-level spatiotemporal features with a high-level segmental classifier. Our spatiotemporal CNN is comprised of a spatial component that uses convolutional filters to capture information about objects and their relationships, and a temporal component that uses large 1D convolutional filters to capture information about how object relationships change across time. These features are used in tandem with a semi-Markov model that models transitions from one action to another. We introduce an efficient constrained segmental inference algorithm for this model that is orders of magnitude faster than the current approach. We highlight the effectiveness of our Segmental Spatiotemporal CNN on cooking and surgical action datasets for which we observe substantially improved performance relative to recent baseline methods.