 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee, Plan, Predict: Language-guided Cognitive Planning with Video Prediction
Paper and Code
Oct 07, 2022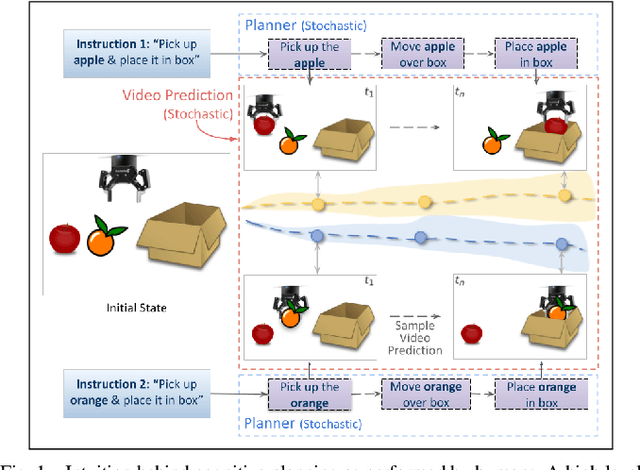
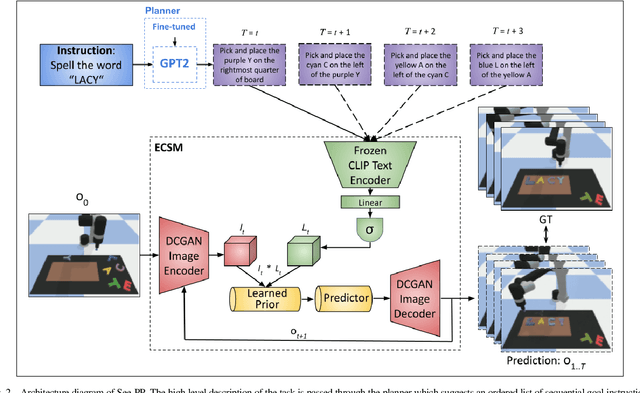
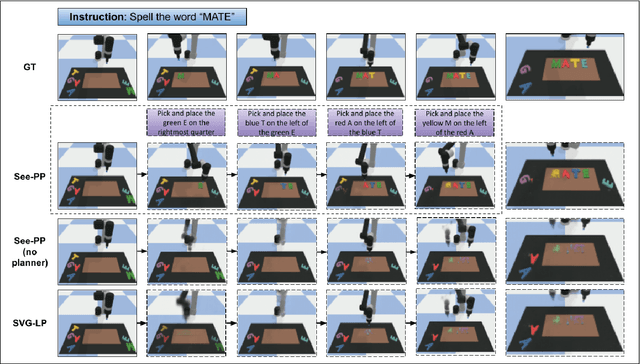

Cognitive planning is the structural decomposition of complex tasks into a sequence of future behaviors. In the computational setting, performing cognitive planning entails grounding plans and concepts in one or more modalities in order to leverage them for low level control. Since real-world tasks are often described in natural language, we devise a cognitive planning algorithm via language-guided video prediction. Current video prediction models do not support conditioning on natural language instructions. Therefore, we propose a new video prediction architecture which leverages the power of pre-trained transformers.The network is endowed with the ability to ground concepts based on natural language input with generalization to unseen objects. We demonstrate the effectiveness of this approach on a new simulation dataset, where each task is defined by a high-level action described in natural language. Our experiments compare our method again stone video generation baseline without planning or action grounding and showcase significant improvements. Our ablation studies highlight an improved generalization to unseen objects that natural language embeddings offer to concept grounding ability, as well as the importance of planning towards visual "imagination" of a task.