 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching for Fast Model Families on Datacenter Accelerators
Paper and Code
Feb 10, 2021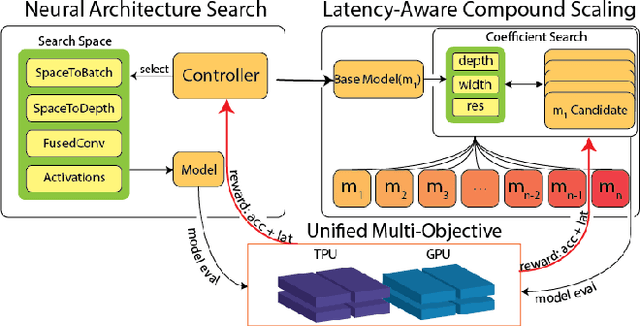

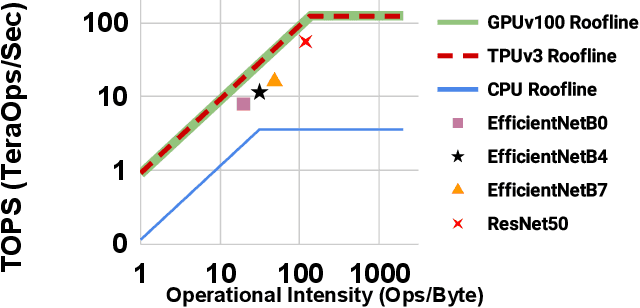

Neural Architecture Search (NAS), together with model scaling, has shown remarkable progress in designing high accuracy and fast convolutional architecture families. However, as neither NAS nor model scaling considers sufficient hardware architecture details, they do not take full advantage of the emerging datacenter (DC) accelerators. In this paper, we search for fast and accurate CNN model families for efficient inference on DC accelerators. We first analyze DC accelerators and find that existing CNNs suffer from insufficient operational intensity, parallelism, and execution efficiency. These insights let us create a DC-accelerator-optimized search space, with space-to-depth, space-to-batch, hybrid fused convolution structures with vanilla and depthwise convolutions, and block-wise activation functions. On top of our DC accelerator optimized neural architecture search space, we further propose a latency-aware compound scaling (LACS), the first multi-objective compound scaling method optimizing both accuracy and latency. Our LACS discovers that network depth should grow much faster than image size and network width, which is quite different from previous compound scaling results. With the new search space and LACS, our search and scaling on datacenter accelerators results in a new model series named EfficientNet-X. EfficientNet-X is up to more than 2X faster than EfficientNet (a model series with state-of-the-art trade-off on FLOPs and accuracy) on TPUv3 and GPUv100, with comparable accuracy. EfficientNet-X is also up to 7X faster than recent RegNet and ResNeSt on TPUv3 and GPUv100.