 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScenes and Surroundings: Scene Graph Generation using Relation Transformer
Paper and Code
Jul 12, 2021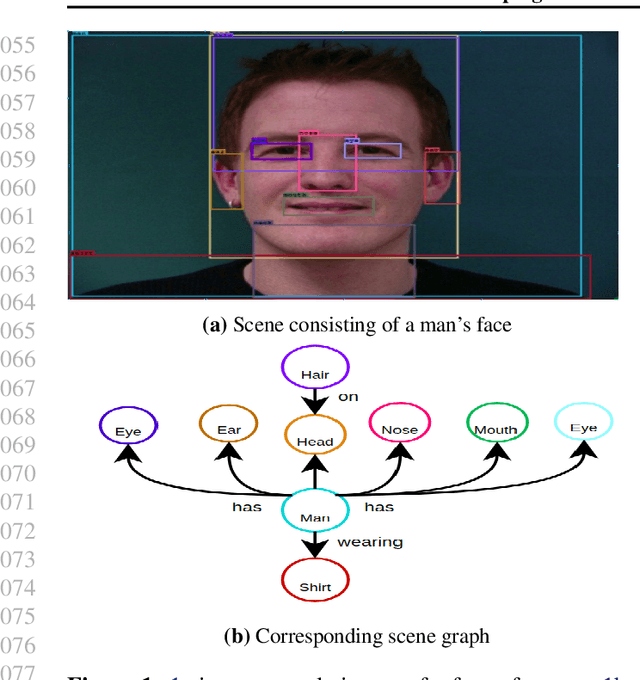
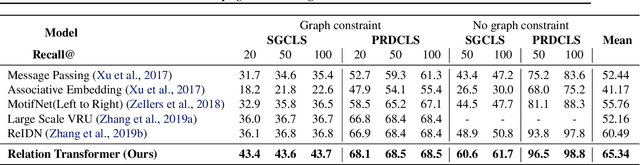
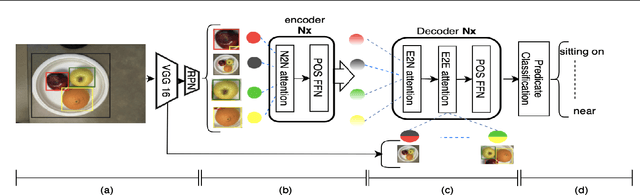
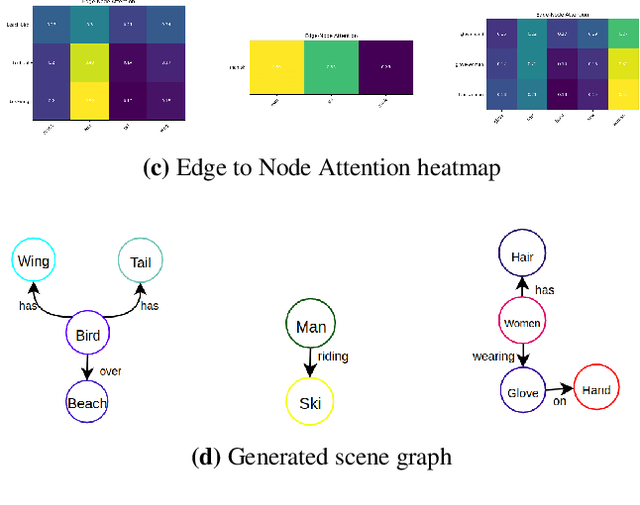
Identifying objects in an image and their mutual relationships as a scene graph leads to a deep understanding of image content. Despite the recent advancement in deep learning, the detection and labeling of visual object relationships remain a challenging task. This work proposes a novel local-context aware architecture named relation transformer, which exploits complex global objects to object and object to edge (relation) interactions. Our hierarchical multi-head attention-based approach efficiently captures contextual dependencies between objects and predicts their relationships. In comparison to state-of-the-art approaches, we have achieved an overall mean \textbf{4.85\%} improvement and a new benchmark across all the scene graph generation tasks on the Visual Genome dataset.