 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Text Recognition with Temporal Convolutional Encoder
Paper and Code
Nov 04, 2019


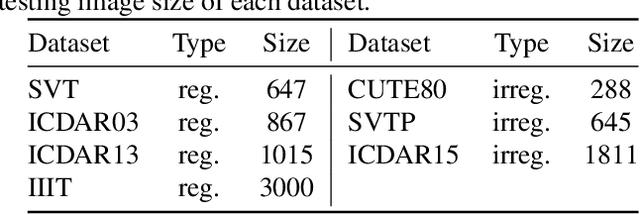
Texts from scene images typically consist of several characters and exhibit a characteristic sequence structure. Existing methods capture the structure with the sequence-to-sequence models by an encoder to have the visual representations and then a decoder to translate the features into the label sequence. In this paper, we study text recognition framework by considering the long-term temporal dependencies in the encoder stage. We demonstrate that the proposed Temporal Convolutional Encoder with increased sequential extents improves the accuracy of text recognition. We also study the impact of different attention modules in convolutional blocks for learning accurate text representations. We conduct comparisons on seven datasets and the experiments demonstrate the effectiveness of our proposed approach.