 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling-up Empirical Risk Minimization: Optimization of Incomplete U-statistics
Paper and Code
Apr 19, 2016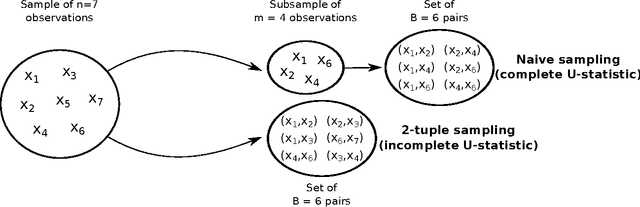


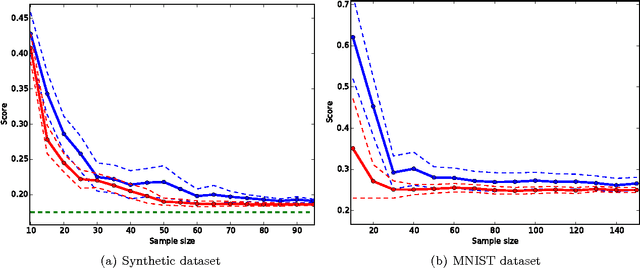
In a wide range of statistical learning problems such as ranking, clustering or metric learning among others, the risk is accurately estimated by $U$-statistics of degree $d\geq 1$, i.e. functionals of the training data with low variance that take the form of averages over $k$-tuples. From a computational perspective, the calculation of such statistics is highly expensive even for a moderate sample size $n$, as it requires averaging $O(n^d)$ terms. This makes learning procedures relying on the optimization of such data functionals hardly feasible in practice. It is the major goal of this paper to show that, strikingly, such empirical risks can be replaced by drastically computationally simpler Monte-Carlo estimates based on $O(n)$ terms only, usually referred to as incomplete $U$-statistics, without damaging the $O_{\mathbb{P}}(1/\sqrt{n})$ learning rate of Empirical Risk Minimization (ERM) procedures. For this purpose, we establish uniform deviation results describing the error made when approximating a $U$-process by its incomplete version under appropriate complexity assumptions. Extensions to model selection, fast rate situations and various sampling techniques are also considered, as well as an application to stochastic gradient descent for ERM. Finally, numerical examples are displayed in order to provide strong empirical evidence that the approach we promote largely surpasses more naive subsampling techniques.