 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for the Few-Shot Adaptation of Pre-trained Image Classifiers
Paper and Code
Oct 18, 2021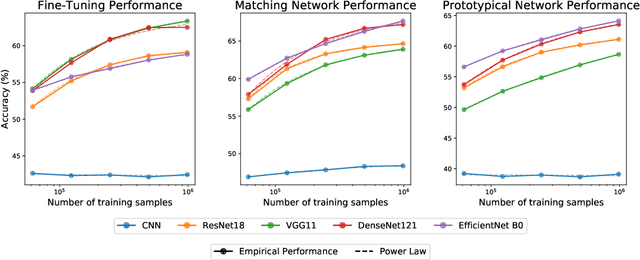

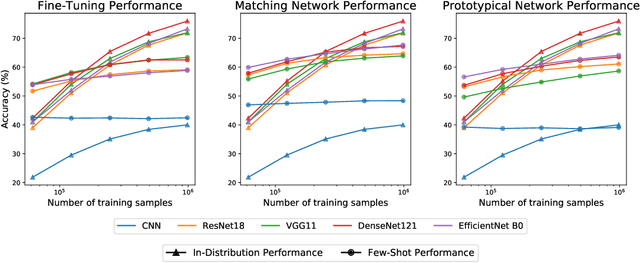
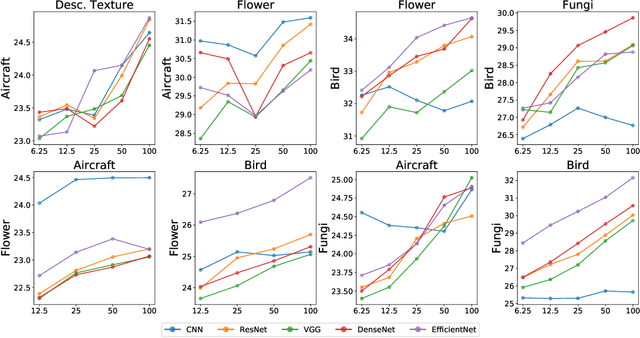
Empirical science of neural scaling laws is a rapidly growing area of significant importance to the future of machine learning, particularly in the light of recent breakthroughs achieved by large-scale pre-trained models such as GPT-3, CLIP and DALL-e. Accurately predicting the neural network performance with increasing resources such as data, compute and model size provides a more comprehensive evaluation of different approaches across multiple scales, as opposed to traditional point-wise comparisons of fixed-size models on fixed-size benchmarks, and, most importantly, allows for focus on the best-scaling, and thus most promising in the future, approaches. In this work, we consider a challenging problem of few-shot learning in image classification, especially when the target data distribution in the few-shot phase is different from the source, training, data distribution, in a sense that it includes new image classes not encountered during training. Our current main goal is to investigate how the amount of pre-training data affects the few-shot generalization performance of standard image classifiers. Our key observations are that (1) such performance improvements are well-approximated by power laws (linear log-log plots) as the training set size increases, (2) this applies to both cases of target data coming from either the same or from a different domain (i.e., new classes) as the training data, and (3) few-shot performance on new classes converges at a faster rate than the standard classification performance on previously seen classes. Our findings shed new light on the relationship between scale and generalization.