 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale Up Nonlinear Component Analysis with Doubly Stochastic Gradients
Paper and Code
Jan 10, 2016
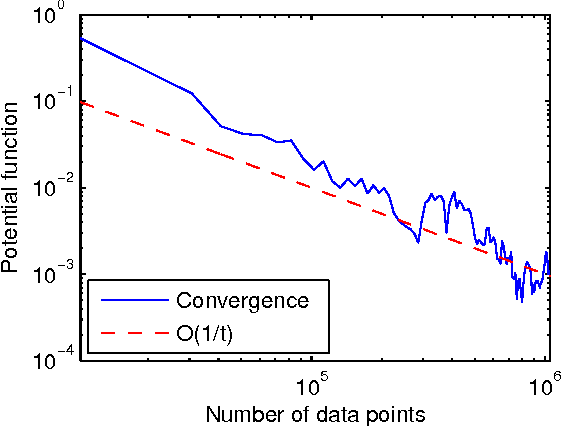

Nonlinear component analysis such as kernel Principle Component Analysis (KPCA) and kernel Canonical Correlation Analysis (KCCA) are widely used in machine learning, statistics and data analysis, but they can not scale up to big datasets. Recent attempts have employed random feature approximations to convert the problem to the primal form for linear computational complexity. However, to obtain high quality solutions, the number of random features should be the same order of magnitude as the number of data points, making such approach not directly applicable to the regime with millions of data points. We propose a simple, computationally efficient, and memory friendly algorithm based on the "doubly stochastic gradients" to scale up a range of kernel nonlinear component analysis, such as kernel PCA, CCA and SVD. Despite the \emph{non-convex} nature of these problems, our method enjoys theoretical guarantees that it converges at the rate $\tilde{O}(1/t)$ to the global optimum, even for the top $k$ eigen subspace. Unlike many alternatives, our algorithm does not require explicit orthogonalization, which is infeasible on big datasets. We demonstrate the effectiveness and scalability of our algorithm on large scale synthetic and real world datasets.