 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Rule-Based Representation Learning for Interpretable Classification
Paper and Code
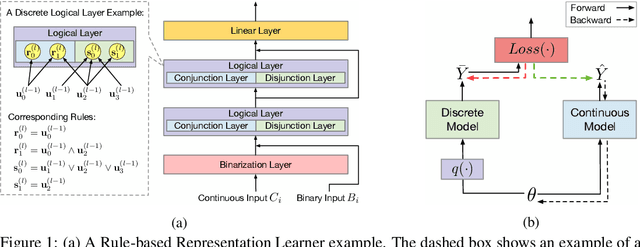
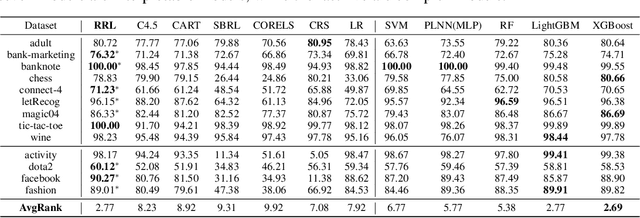
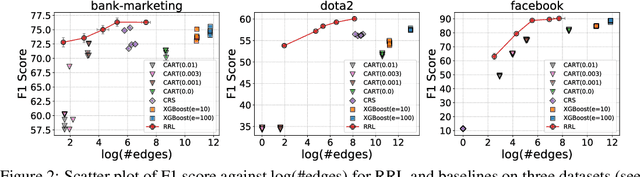

Rule-based models, e.g., decision trees, are widely used in scenarios demanding high model interpretability for their transparent inner structures and good model expressivity. However, rule-based models are hard to optimize, especially on large data sets, due to their discrete parameters and structures. Ensemble methods and fuzzy/soft rules are commonly used to improve performance, but they sacrifice the model interpretability. To obtain both good scalability and interpretability, we propose a new classifier, named Rule-based Representation Learner (RRL), that automatically learns interpretable non-fuzzy rules for data representation and classification. To train the non-differentiable RRL effectively, we project it to a continuous space and propose a novel training method, called Gradient Grafting, that can directly optimize the discrete model using gradient descent. An improved design of logical activation functions is also devised to increase the scalability of RRL and enable it to discretize the continuous features end-to-end. Exhaustive experiments on nine small and four large data sets show that RRL outperforms the competitive interpretable approaches and can be easily adjusted to obtain a trade-off between classification accuracy and model complexity for different scenarios. Our code is available at: https://github.com/12wang3/rrl.