 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable MCMC for Large Data Problems using Data Subsampling and the Difference Estimator
Paper and Code
Aug 02, 2017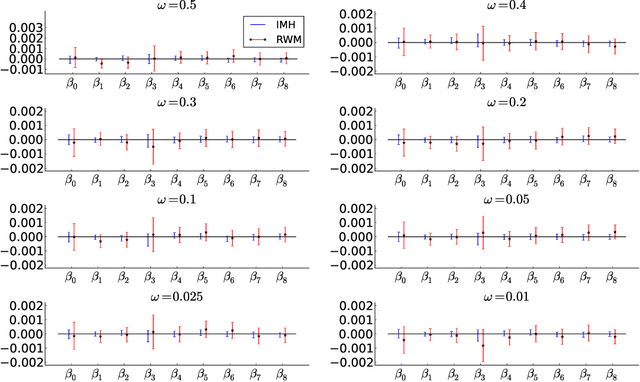
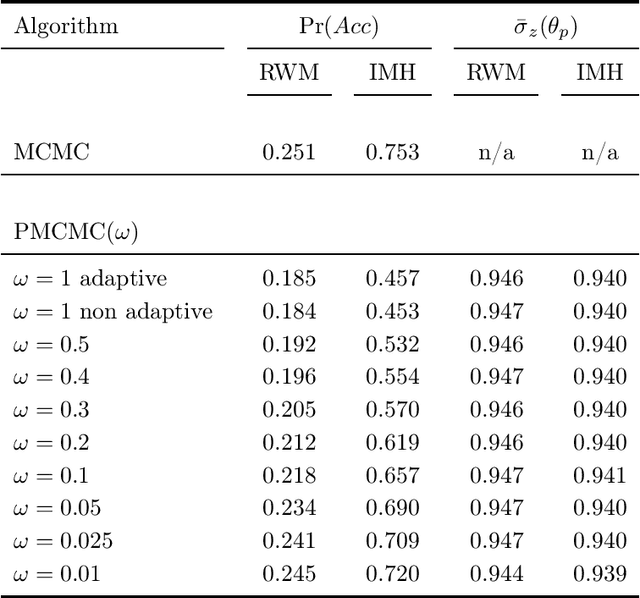
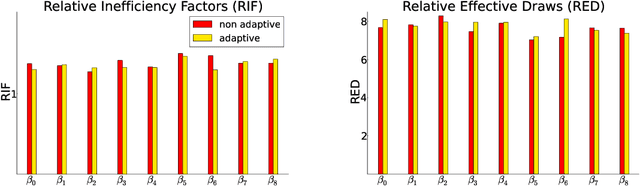
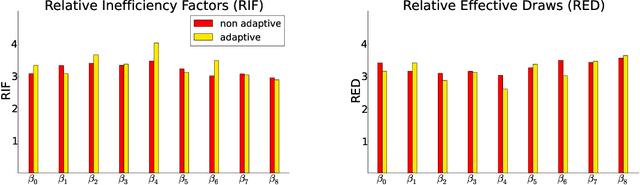
We propose a generic Markov Chain Monte Carlo (MCMC) algorithm to speed up computations for datasets with many observations. A key feature of our approach is the use of the highly efficient difference estimator from the survey sampling literature to estimate the log-likelihood accurately using only a small fraction of the data. Our algorithm improves on the $O(n)$ complexity of regular MCMC by operating over local data clusters instead of the full sample when computing the likelihood. The likelihood estimate is used in a Pseudo-marginal framework to sample from a perturbed posterior which is within $O(m^{-1/2})$ of the true posterior, where $m$ is the subsample size. The method is applied to a logistic regression model to predict firm bankruptcy for a large data set. We document a significant speed up in comparison to the standard MCMC on the full dataset.