 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Lipschitz Residual Networks with Convex Potential Flows
Paper and Code
Oct 25, 2021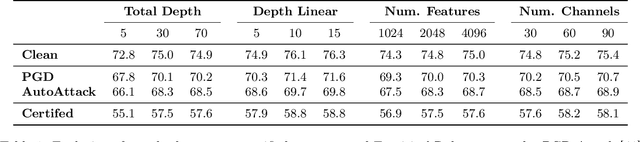
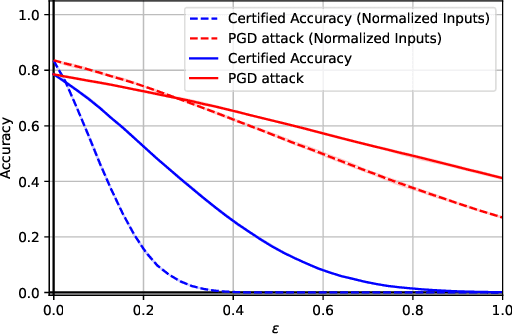
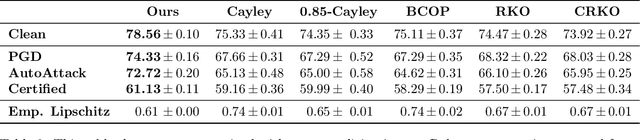

The Lipschitz constant of neural networks has been established as a key property to enforce the robustness of neural networks to adversarial examples. However, recent attempts to build $1$-Lipschitz Neural Networks have all shown limitations and robustness have to be traded for accuracy and scalability or vice versa. In this work, we first show that using convex potentials in a residual network gradient flow provides a built-in $1$-Lipschitz transformation. From this insight, we leverage the work on Input Convex Neural Networks to parametrize efficient layers with this property. A comprehensive set of experiments on CIFAR-10 demonstrates the scalability of our architecture and the benefit of our approach for $\ell_2$ provable defenses. Indeed, we train very deep and wide neural networks (up to $1000$ layers) and reach state-of-the-art results in terms of standard and certified accuracy, along with empirical robustness, in comparison with other $1$-Lipschitz architectures.