 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Consistency Training for Graph Neural Networks via Self-Ensemble Self-Distillation
Paper and Code
Oct 12, 2021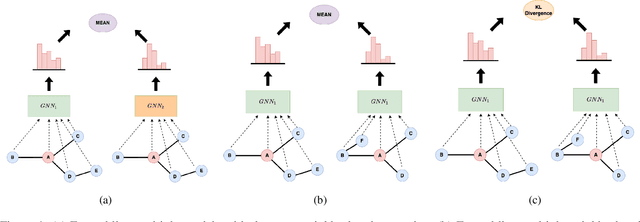
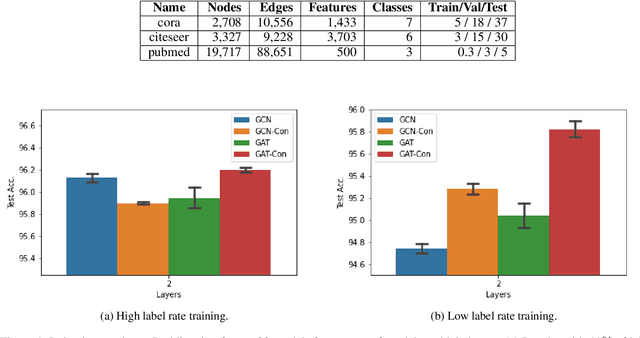
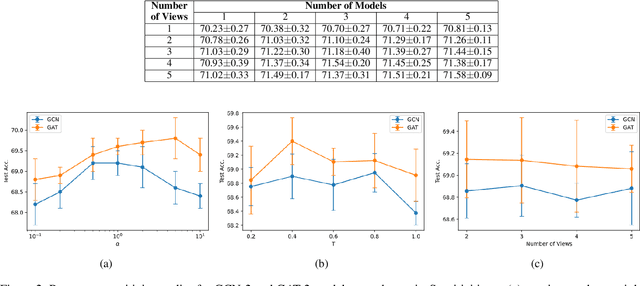
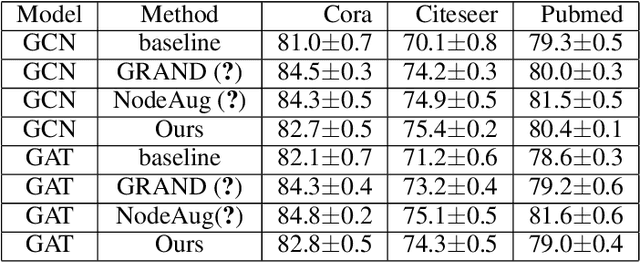
Consistency training is a popular method to improve deep learning models in computer vision and natural language processing. Graph neural networks (GNNs) have achieved remarkable performance in a variety of network science learning tasks, but to date no work has studied the effect of consistency training on large-scale graph problems. GNNs scale to large graphs by minibatch training and subsample node neighbors to deal with high degree nodes. We utilize the randomness inherent in the subsampling of neighbors and introduce a novel consistency training method to improve accuracy. For a target node we generate different neighborhood expansions, and distill the knowledge of the average of the predictions to the GNN. Our method approximates the expected prediction of the possible neighborhood samples and practically only requires a few samples. We demonstrate that our training method outperforms standard GNN training in several different settings, and yields the largest gains when label rates are low.