 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling without Replacement Leads to Faster Rates in Finite-Sum Minimax Optimization
Paper and Code
Jun 07, 2022
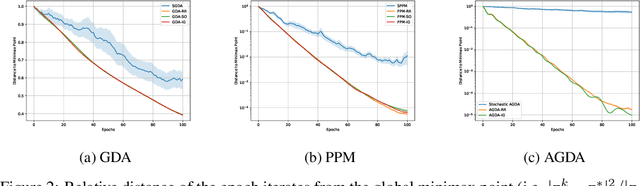
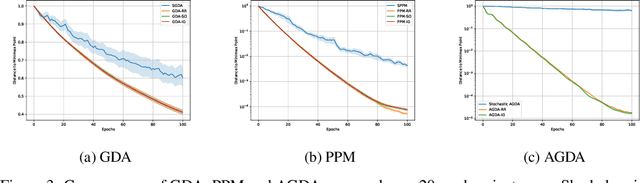
We analyze the convergence rates of stochastic gradient algorithms for smooth finite-sum minimax optimization and show that, for many such algorithms, sampling the data points without replacement leads to faster convergence compared to sampling with replacement. For the smooth and strongly convex-strongly concave setting, we consider gradient descent ascent and the proximal point method, and present a unified analysis of two popular without-replacement sampling strategies, namely Random Reshuffling (RR), which shuffles the data every epoch, and Single Shuffling or Shuffle Once (SO), which shuffles only at the beginning. We obtain tight convergence rates for RR and SO and demonstrate that these strategies lead to faster convergence than uniform sampling. Moving beyond convexity, we obtain similar results for smooth nonconvex-nonconcave objectives satisfying a two-sided Polyak-{\L}ojasiewicz inequality. Finally, we demonstrate that our techniques are general enough to analyze the effect of data-ordering attacks, where an adversary manipulates the order in which data points are supplied to the optimizer. Our analysis also recovers tight rates for the incremental gradient method, where the data points are not shuffled at all.