Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling Approach Matters: Active Learning for Robotic Language Acquisition
Paper and Code
Nov 16, 2020
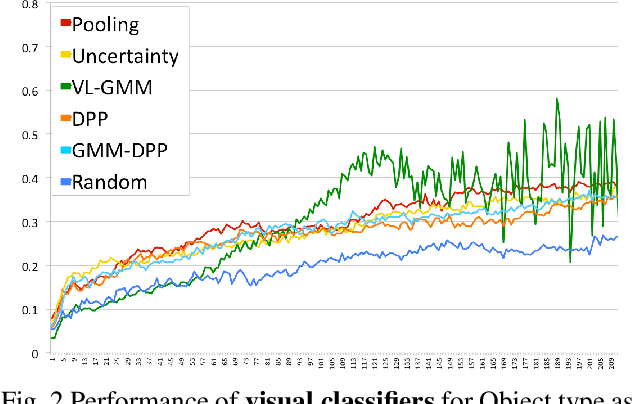


Ordering the selection of training data using active learning can lead to improvements in learning efficiently from smaller corpora. We present an exploration of active learning approaches applied to three grounded language problems of varying complexity in order to analyze what methods are suitable for improving data efficiency in learning. We present a method for analyzing the complexity of data in this joint problem space, and report on how characteristics of the underlying task, along with design decisions such as feature selection and classification model, drive the results. We observe that representativeness, along with diversity, is crucial in selecting data samples.
* To appear in IEEE Big Data 2020
View paper on