 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Efficient Reinforcement Learning via Conservative Model-Based Actor-Critic
Paper and Code
Dec 16, 2021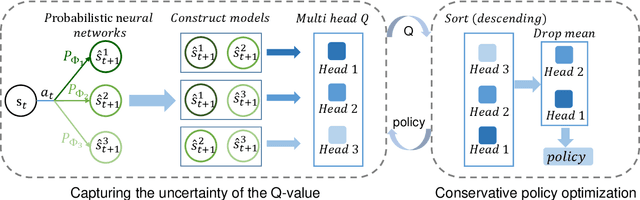



Model-based reinforcement learning algorithms, which aim to learn a model of the environment to make decisions, are more sample efficient than their model-free counterparts. The sample efficiency of model-based approaches relies on whether the model can well approximate the environment. However, learning an accurate model is challenging, especially in complex and noisy environments. To tackle this problem, we propose the conservative model-based actor-critic (CMBAC), a novel approach that achieves high sample efficiency without the strong reliance on accurate learned models. Specifically, CMBAC learns multiple estimates of the Q-value function from a set of inaccurate models and uses the average of the bottom-k estimates -- a conservative estimate -- to optimize the policy. An appealing feature of CMBAC is that the conservative estimates effectively encourage the agent to avoid unreliable "promising actions" -- whose values are high in only a small fraction of the models. Experiments demonstrate that CMBAC significantly outperforms state-of-the-art approaches in terms of sample efficiency on several challenging tasks, and the proposed method is more robust than previous methods in noisy environments.