 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalyPath360: Saliency and Scanpath Prediction Framework for Omnidirectional Images
Paper and Code
Jan 01, 2022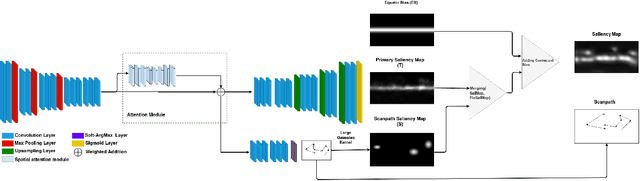



This paper introduces a new framework to predict visual attention of omnidirectional images. The key setup of our architecture is the simultaneous prediction of the saliency map and a corresponding scanpath for a given stimulus. The framework implements a fully encoder-decoder convolutional neural network augmented by an attention module to generate representative saliency maps. In addition, an auxiliary network is employed to generate probable viewport center fixation points through the SoftArgMax function. The latter allows to derive fixation points from feature maps. To take advantage of the scanpath prediction, an adaptive joint probability distribution model is then applied to construct the final unbiased saliency map by leveraging the encoder decoder-based saliency map and the scanpath-based saliency heatmap. The proposed framework was evaluated in terms of saliency and scanpath prediction, and the results were compared to state-of-the-art methods on Salient360! dataset. The results showed the relevance of our framework and the benefits of such architecture for further omnidirectional visual attention prediction tasks.