 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency Prediction with External Knowledge
Paper and Code
Jul 27, 2020
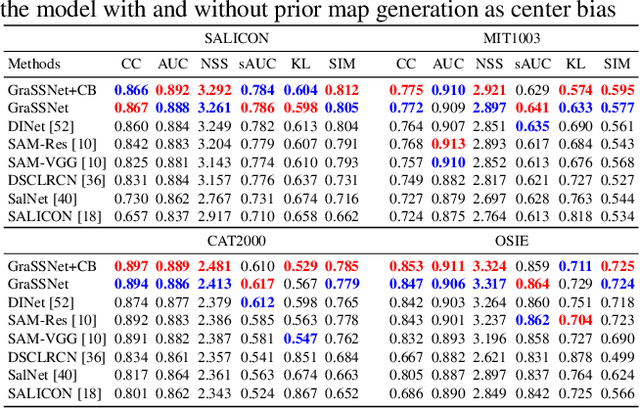
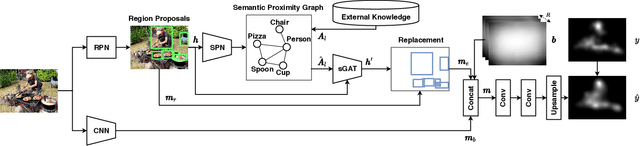

The last decades have seen great progress in saliency prediction, with the success of deep neural networks that are able to encode high-level semantics. Yet, while humans have the innate capability in leveraging their knowledge to decide where to look (e.g. people pay more attention to familiar faces such as celebrities), saliency prediction models have only been trained with large eye-tracking datasets. This work proposes to bridge this gap by explicitly incorporating external knowledge for saliency models as humans do. We develop networks that learn to highlight regions by incorporating prior knowledge of semantic relationships, be it general or domain-specific, depending on the task of interest. At the core of the method is a new Graph Semantic Saliency Network (GraSSNet) that constructs a graph that encodes semantic relationships learned from external knowledge. A Spatial Graph Attention Network is then developed to update saliency features based on the learned graph. Experiments show that the proposed model learns to predict saliency from the external knowledge and outperforms the state-of-the-art on four saliency benchmarks.