 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency-based Sequential Image Attention with Multiset Prediction
Paper and Code
Nov 14, 2017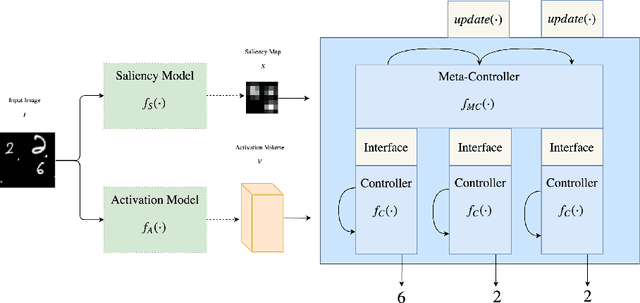
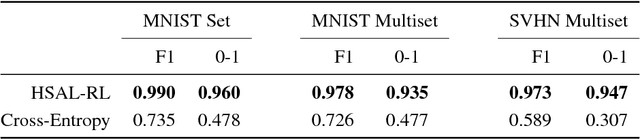


Humans process visual scenes selectively and sequentially using attention. Central to models of human visual attention is the saliency map. We propose a hierarchical visual architecture that operates on a saliency map and uses a novel attention mechanism to sequentially focus on salient regions and take additional glimpses within those regions. The architecture is motivated by human visual attention, and is used for multi-label image classification on a novel multiset task, demonstrating that it achieves high precision and recall while localizing objects with its attention. Unlike conventional multi-label image classification models, the model supports multiset prediction due to a reinforcement-learning based training process that allows for arbitrary label permutation and multiple instances per label.