 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeguarded Learned Convex Optimization
Paper and Code

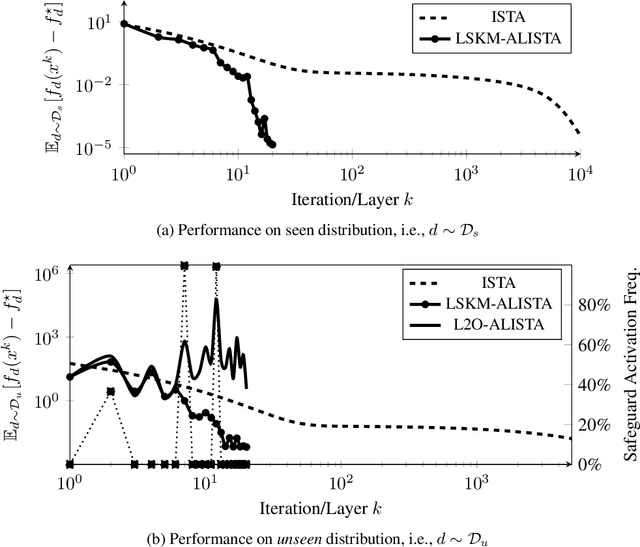
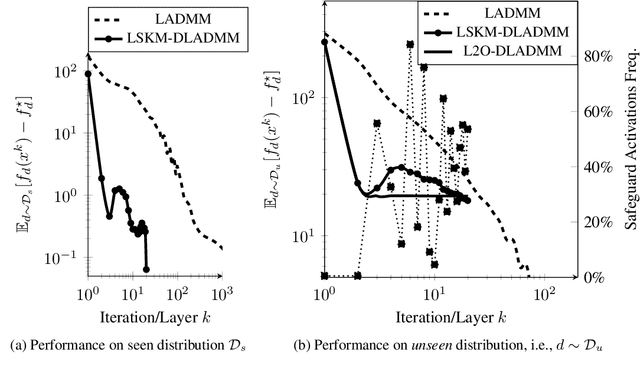

Many applications require repeatedly solving a certain type of optimization problem, each time with new (but similar) data. Data-driven algorithms can "learn to optimize" (L2O) with much fewer iterations and with similar cost per iteration as general-purpose optimization algorithms. L2O algorithms are often derived from general-purpose algorithms, but with the inclusion of (possibly many) tunable parameters. Exceptional performance has been demonstrated when the parameters are optimized for a particular distribution of data. Unfortunately, it is impossible to ensure all L2O algorithms always converge to a solution. However, we present a framework that uses L2O updates together with a safeguard to guarantee convergence for convex problems with proximal and/or gradient oracles. The safeguard is simple and computationally cheap to implement, and it should be activated only when the current L2O updates would perform poorly or appear to diverge. This approach yields the numerical benefits of employing machine learning methods to create rapid L2O algorithms while still guaranteeing convergence. Our numerical examples demonstrate the efficacy of this approach for existing and new L2O schemes.