 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Pontryagin Differentiable Programming
Paper and Code


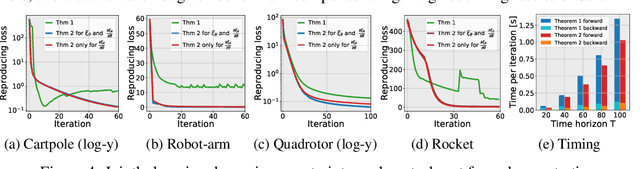
We propose a Safe Pontryagin Differentiable Programming (Safe PDP) methodology, which establishes a theoretical and algorithmic safe differentiable framework to solve a broad class of safety-critical learning and control tasks -- problems that require the guarantee of both immediate and long-term constraint satisfaction at any stage of the learning and control progress. In the spirit of interior-point methods, Safe PDP handles different types of state and input constraints by incorporating them into the cost and loss through barrier functions. We prove the following fundamental features of Safe PDP: first, both the constrained solution and its gradient in backward pass can be approximated by solving a more efficient unconstrained counterpart; second, the approximation for both the solution and its gradient can be controlled for arbitrary accuracy using a barrier parameter; and third, importantly, any intermediate results throughout the approximation and optimization are strictly respecting all constraints, thus guaranteeing safety throughout the entire learning and control process. We demonstrate the capabilities of Safe PDP in solving various safe learning and control tasks, including safe policy optimization, safe motion planning, and learning MPCs from demonstrations, on different challenging control systems such as 6-DoF maneuvering quadrotor and 6-DoF rocket powered landing.